HJ16 购物单
HJ16 购物单
描述
王强决定把年终奖用于购物,他把想买的物品分为两类:主件与附件,附件是从属于某个主件的,下表就是一些主件与附件的例子: ![[../photo/9.png]]
如果要买归类为附件的物品,必须先买该附件所属的主件,且每件物品只能购买一次。
每个主件可以有 0 个、 1 个或 2 个附件。附件不再有从属于自己的附件。
王强查到了每件物品的价格(都是 10 元的整数倍),而他只有 N 元的预算。除此之外,他给每件物品规定了一个重要度,用整数 1 ~ 5 表示。他希望在花费不超过 N 元的前提下,使自己的满意度达到最大。
满意度是指所购买的每件物品的价格与重要度的乘积的总和,假设设第ii件物品的价格为v[i]v[i],重要度为w[i]w[i],共选中了kk件物品,编号依次为j_1,j_2,...,j_kj1,j2,...,jk,则满意度为:v[j_1]*w[j_1]+v[j_2]*w[j_2]+ … +v[j_k]*w[j_k]v[j1]∗w[j1]+v[j2]∗w[j2]+…+v[jk]∗w[jk]。(其中 * 为乘号)
请你帮助王强计算可获得的最大的满意度。
输入描述:
输入的第 1 行,为两个正整数N,m,用一个空格隔开:
(其中 N ( N<32000 )表示总钱数, m (m <60 )为可购买的物品的个数。) 从第 2 行到第 m+1 行,第 j 行给出了编号为 j-1 的物品的基本数据,每行有 3 个非负整数 v p q (其中 v 表示该物品的价格( v<10000 ), p 表示该物品的重要度( 1 ~ 5 ), q 表示该物品是主件还是附件。如果 q=0 ,表示该物品为主件,如果 q>0 ,表示该物品为附件, q 是所属主件的编号)
输出描述:
输出一个正整数,为张强可以获得的最大的满意度。
示例1
输入: 1000 5 800 2 0 400 5 1 300 5 1 400 3 0 500 2 0
输出: 2200
说明: 由第1行可知总钱数N为50以及希望购买的物品个数m为5; 第2和第3行的q为5,说明它们都是编号为5的物品的附件; 第46行的q都为0,说明它们都是主件,它们的编号依次为35; 所以物品的价格与重要度乘积的总和的最大值为101+203+20*3=130
方法一:动态规划
实现思路
我们规定
dp[i][j]表示在 [ 前i] 个物品里面 [ 预算值(背包)容量允许为j] 的情况下可以获得的最大的价值加权和对于01背包问题,我们的动态规划决策是当前物品是否要选择。
dp[i][j]=max(dp[i−1][j],dp[i−1][j−w[j]]+v[j])dp[i][j] = max(dp[i-1][j], dp[i-1][j-w[j]] + v[j])dp[i][j]=max(dp[i−1][j],dp[i−1][j−w[j]]+v[j])
但是由于本题有主附件的选择考虑,因此我们将选择的情况划分为更多种类
- 不选择当前物品
- 选择【当前主件物品】
- 选择【当前主件 + 附件1】
- 选额【当前主件 + 附件2】
- 选择【当前主件 + 附件1 + 附件2】
因此有动态转移方程
dp[i][j]=max(dp[i−1][j],四种选择方案)dp[i][j] = max(dp[i-1][j], 四种选择方案)dp[i][j]=max(dp[i−1][j],四种选择方案)
同时本题处理上的一个关键内容在于如何访问我们的所有物品。依据我们的方案,我们需要将物品重新处理成新的数据结构,这种结构要求一定是主件优先被访问到,并且绑定主件和附件的关系
并且由于价格都是10的整数倍,我们统一在数据处理的时候都缩小十倍处理
因此我们有如下的表格结构
假设现在的输入内容为: ![[../photo/10.png]] 重新组织结构后(价格和加权价值全部是除以10后的结果) ![[../photo/11.png]] 
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
int main() {
int N, m, v, p, q;;
cin >> N >> m;
N /= 10;
// 重新处理数据,整理成 "主件(价格+加权价值)+附件1(价格+加权价值)+附件2(价格+加权价值)" 的结构
vector<vector<int>> items(m + 1, vector<int>(6, 0));
for(int i = 1; i <= m; i++) {
cin >> v >> p >> q; // 价格 权重 主附
v /= 10;
p *= v;
if(q == 0) { // 如果当前是主件
items[i][0] = v;
items[i][1] = p;
} else if(items[q][2] == 0) { // 如果当前附件1位置为空
items[q][2] = v;
items[q][3] = p;
} else { // 只剩下附件2的位置
items[q][4] = v;
items[q][5] = p;
}
}
vector<vector<int>> dp(m + 1, vector<int>(N + 1, 0));
// dp[i][j] 表示在前i个里面预算值(背包)容量允许为j的情况下可以获得的最大的价值加权和
for(int i = 1; i <= m; i++) {
for(int j = 1; j <= N; j++) {
int a = items[i][0], d = items[i][1]; // 主件的价格+加权价值
int b = items[i][2], e = items[i][3]; // 附件1的价格+加权价值
int c = items[i][4], f = items[i][5]; // 附件2的价格+加权价值
dp[i][j] = dp[i-1][j];
if(j >= a) dp[i][j] = max(dp[i-1][j-a] + d, dp[i-1][j]); // 只挑选一个主件
if(j >= a+b) dp[i][j] = max(dp[i-1][j-a-b] + d+e, dp[i][j]); // 挑选主件+附件1
if(j >= a+c) dp[i][j] = max(dp[i-1][j-a-c] + d+f, dp[i][j]); // 挑选主件+附件2
if(j >= a+b+c) dp[i][j] = max(dp[i-1][j-a-b-c] + d+e+f, dp[i][j]); // 挑选主件+附件1+附件2
}
}
cout << dp[m][N] * 10 <<endl;
return 0;
}

方法二:空间记忆递归
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
int recursion(int m, int N, vector<vector<int>>& price, vector<vector<int>>& multi_sum, vector<vector<int>>& dp){
if(m == 0 || N == 0)
return dp[m][N] = 0;
else if(price[m][0] > N){ //买不了该主件,进入下一个
if(dp[m - 1][N] == -1)
dp[m - 1][N] = recursion(m - 1, N, price, multi_sum, dp);
return dp[m - 1][N];
}
else{ //可以装下主件的情况
if(dp[m - 1][N] == -1)
dp[m - 1][N] = recursion(m - 1, N, price, multi_sum, dp); //不装
if(dp[m - 1][N - price[m][0]] == -1)
dp[m - 1][N - price[m][0]] = recursion(m - 1, N - price[m][0], price, multi_sum, dp); //装
dp[m][N] = max(dp[m - 1][N], dp[m - 1][N - price[m][0]] + multi_sum[m][0]); //对于第m项主件的情况
if(N >= price[m][0] + price[m][1]){//买得起主件+第一个附件
if(dp[m - 1][N - price[m][0] - price[m][1]] == -1)
dp[m - 1][N - price[m][0] - price[m][1]] = recursion(m - 1, N - price[m][0] - price[m][1], price, multi_sum, dp);
dp[m][N] = max(dp[m][N], dp[m - 1][N - price[m][0] - price[m][1]] + multi_sum[m][0] + multi_sum[m][1]);
}
if(N >= price[m][0] + price[m][2]){//买得起主件+第2个附件
if(dp[m - 1][N - price[m][0] - price[m][2]] == -1)
dp[m - 1][N - price[m][0] - price[m][2]] = recursion(m - 1, N - price[m][0] - price[m][2], price, multi_sum, dp);
dp[m][N] = max(dp[m][N], dp[m - 1][N - price[m][0] - price[m][2]] + multi_sum[m][0] + multi_sum[m][2]);
}
if(N >= price[m][0] + price[m][1] + price[m][2]){//买得起主件+两个附件
if(dp[m - 1][N - price[m][0] - price[m][1] - price[m][2]] == -1)
dp[m - 1][N - price[m][0] - price[m][1] - price[m][2]] = recursion(m - 1, N - price[m][0] - price[m][1] - price[m][2], price, multi_sum, dp);
dp[m][N] = max(dp[m][N], dp[m - 1][N - price[m][0] - price[m][1] - price[m][2]] + multi_sum[m][0] + multi_sum[m][1] + multi_sum[m][2]);
}
return dp[m][N];
}
return 0;
}
int main(){
int N, m;
cin >> N >> m;
N /= 10; //所有价格及金钱都是10倍数
vector<vector<int> > price(m + 1, vector<int>(3, 0)); //记录价格及附件价格
vector<vector<int> > multi_sum(m + 1, vector<int>(3, 0)); //记录重要度*价格
vector<vector<int> > dp(m + 1, vector<int>(N + 1, -1)); //dp数组
for(int i = 1; i <= m; i++){ //遍历输入,将所有价格及乘积信息录入数组
int v, p, q;
cin >> v >> p >> q; //输入价格、重要度、附属信息
v /= 10; //所有价格及金钱都是10倍数
p *= v; //重要度乘上价格
if(q == 0){ //主件
price[i][0] = v;
multi_sum[i][0] = p;
}else{ //附件
if(price[q][1] == 0){ //第一个附件
price[q][1] = v;
multi_sum[q][1] = p;
}else{ //第二个附件
price[q][2] = v;
multi_sum[q][2] = p;
}
}
}
cout << recursion(m, N, price, multi_sum, dp) * 10 << endl; //输出要乘回10倍
return 0;
}
方法三:动态规划空间优化
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
int main() {
int N, m, v, p, q;;
cin >> N >> m;
N /= 10;
// 重新处理数据,整理成 "主件(价格+加权价值)+附件1(价格+加权价值)+附件2(价格+加权价值)" 的结构
vector<vector<int>> items(m + 1, vector<int>(6, 0));
for(int i = 1; i <= m; i++) {
cin >> v >> p >> q; // 价格 权重 主附
v /= 10;
p *= v;
if(q == 0) { // 如果当前是主件
items[i][0] = v;
items[i][1] = p;
} else if(items[q][2] == 0) { // 如果当前附件1位置为空
items[q][2] = v;
items[q][3] = p;
} else { // 只剩下附件2的位置
items[q][4] = v;
items[q][5] = p;
}
}
vector<vector<int>> dp(m + 1, vector<int>(N + 1, 0));
// dp[i][j] 表示在前i个里面预算值(背包)容量允许为j的情况下可以获得的最大的价值加权和
for(int i = 1; i <= m; i++) {
for(int j = 1; j <= N; j++) {
int a = items[i][0], d = items[i][1]; // 主件的价格+加权价值
int b = items[i][2], e = items[i][3]; // 附件1的价格+加权价值
int c = items[i][4], f = items[i][5]; // 附件2的价格+加权价值
dp[i][j] = dp[i-1][j];
if(j >= a) dp[i][j] = max(dp[i-1][j-a] + d, dp[i-1][j]); // 只挑选一个主件
if(j >= a+b) dp[i][j] = max(dp[i-1][j-a-b] + d+e, dp[i][j]); // 挑选主件+附件1
if(j >= a+c) dp[i][j] = max(dp[i-1][j-a-c] + d+f, dp[i][j]); // 挑选主件+附件2
if(j >= a+b+c) dp[i][j] = max(dp[i-1][j-a-b-c] + d+e+f, dp[i][j]); // 挑选主件+附件1+附件2
}
}
cout << dp[m][N] * 10 <<endl;
return 0;
}
HJ17 坐标移动
描述
开发一个坐标计算工具, A表示向左移动,D表示向右移动,W表示向上移动,S表示向下移动。从(0,0)点开始移动,从输入字符串里面读取一些坐标,并将最终输入结果输出到输出文件里面。
#include <iostream>
#include <algorithm>
#include <cctype>
using namespace std;
/* check if a cmd is valid */
bool isValid(string const& cmd);
/* change x and y according to cmd */
void move(string const& cmd, int& x, int& y);
/* MAIN FUNC */
int main() {
int x = 0, y = 0;
string cmds, cmd = "";
getline(cin, cmds, '\n');
for (auto s: cmds) {
if (s == ';') {
if (isValid(cmd)) {move(cmd, x, y);}
cmd = "";
}
else {cmd += s;}
}
cout << x << "," << y;
return 0;
}
bool isValid(string const& cmd) {
if (cmd.length() <= 1) {return false;}
if (!isalpha(cmd[0])) {return false;}
for (size_t i = 1; i < cmd.length(); ++i) {
if (!isdigit(cmd[i])) {return false;}
}
return true;
}
void move(string const& cmd, int& x, int& y) {
int num = stoi(cmd.substr(1));
switch(cmd[0]) {
case 'W': y += num; break;
case 'S': y -= num; break;
case 'D': x += num; break;
case 'A': x -= num; break;
}
}
HJ18 识别有效的IP地址和掩码并进行分类统计
描述
请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。
所有的IP地址划分为 A,B,C,D,E五类
A类地址从1.0.0.0到126.255.255.255;
B类地址从128.0.0.0到191.255.255.255;
C类地址从192.0.0.0到223.255.255.255;
D类地址从224.0.0.0到239.255.255.255;
E类地址从240.0.0.0到255.255.255.255
私网IP范围是:
从10.0.0.0到10.255.255.255
从172.16.0.0到172.31.255.255
从192.168.0.0到192.168.255.255
子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码)
(注意二进制下全是1或者全是0均为非法子网掩码)
注意:
类似于【0...】和【127...】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时请忽略
私有IP地址和A,B,C,D,E类地址是不冲突的
输入描述:
多行字符串。每行一个IP地址和掩码,用~隔开。
请参考帖子https://www.nowcoder.com/discuss/276处理循环输入的问题。
输出描述:
统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。
方法一:遍历检查

#include<iostream>
#include<string>
#include<vector>
using namespace std;
int main(){
vector<int> arr(7, 0); //分别对应题目的7个类别
string s;
while(getline(cin, s)){
int n = s.length();
vector<int> ips; //记录ip地址的数字
bool bad = false;
bool isnum = false;
int num = 0;
for(int i = 0; i < n; i++){ //遍历该ip字符串
if(s[i] == '.' || s[i] == '~'){ //以.或者~分割
if(isnum){
if(num > 255){
bad = true; //错误ip,数字不能超过255
break;
}
ips.push_back(num);
isnum = false;
num = 0;
}else{
arr[5]++; //错误地址
bad = true;
break;
}
}else if(s[i] >= '0' && s[i] <= '9'){
isnum = true;
num = num * 10 + s[i] - '0'; //计算数字
}else{
arr[5]++;
isnum = false; //错误地址,数字部分还有非数字
bad = true;
break;
}
}
if(isnum)
ips.push_back(num); //最后一个数字
if(ips[0] == 0 || ips[0] == 127 || bad)
continue; //忽略0或者127开头的地址,错误ip已经统计了过了,可以忽略
int mask = 4; //查看掩码的数字
while(mask < 8 && ips[mask] == 255)
mask++; //找到掩码第一个不全为1的数
if(mask == 8){ //掩码全1也是不合法
arr[5]++;
continue;
}else if(ips[mask] == 254 || ips[mask] == 252 || ips[mask] == 248 || ips[mask] == 240 || ips[mask] == 224 || ips[mask] == 191 || ips[mask] == 128)
mask++; //各类掩码含1的最后一位
while(mask < 8 && ips[mask] == 0)
mask++;
if(mask != 8){ //掩码后半部分不能有1
arr[5]++;
continue;
}
if(ips[0] >= 1 && ips[0] <= 126)
arr[0]++; //A类地址
else if(ips[0] >= 128 && ips[0] <= 191)
arr[1]++; //B类地址
else if(ips[0] >= 192 && ips[0] <= 223)
arr[2]++; //C类地址
else if(ips[0] >= 224 && ips[0] <= 239)
arr[3]++; //D类地址
else if(ips[0] >= 240 && ips[0] <= 255)
arr[4]++; //E类地址
if(ips[0] == 10)
arr[6]++; //私有地址10开头的
else if(ips[0] == 172 && (ips[1] >= 16 && ips[1] <= 31))
arr[6]++; //私有地址172.16.0.0-172.31.255.255
else if(ips[0] == 192 && ips[1] == 168)
arr[6]++; //私有地址192.168.0.0-192.168.255.255
}
for(int i = 0; i < 7; i++){ //输出
cout << arr[i];
if(i != 6)
cout << " ";
}
cout << endl;
return 0;
}
方法二:正则表达式
import re
#各类的地址的正则表达式
error_pattern = re.compile(r'1+0+')
A_pattern = re.compile(r'((12[0-6]|1[0-1]\d|[1-9]\d|[1-9])\.)((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
B_pattern = re.compile(r'(12[8-9]|1[3-8]\d|19[0-1])\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
C_pattern = re.compile(r'(19[2-9]|2[0-1]\d|22[0-3])\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
D_pattern = re.compile(r'(22[4-9]|23\d)\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
E_pattern = re.compile(r'(24\d|25[0-5])\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)')
self_pattern = re.compile(r'((10\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d))|(172\.(1[6-9]|2\d|3[0-1])\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d))|(192\.168\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)))')
escape = re.compile(r'((0|127)\.((1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d)\.){2}(1\d\d|2[0-4]\d|25[0-5]|[1-9]\d|\d))')
def judge_mask(line):
if line == '255.255.255.255' or line == '0.0.0.0': #全0全1
return 0
judge = line.split('.') #按照点分割数字
res = ''
for j in judge:
res += '{:0>8b}'.format(int(j))
res = re.fullmatch(error_pattern, res)
if res == None:
return 0
else:
return 1
def judge(pattern, line): #匹配函数
if re.fullmatch(pattern, line) != None:
return 1
else:
return 0
arr = [0]*7
while True:
try:
line = input().split('~') #从~分割IP地址和掩码
if line[0][0:4] == "127." or line[0][0:2] == "0.": #优先判断127或者0开头的
continue
if judge_mask(line[1]): #先判断掩码是否正确
#正则比较各个IP地址
if judge(self_pattern, line[0]): #私有与其他的不冲突,优先单独匹配
arr[6] += 1
if judge(A_pattern, line[0]):
arr[0] += 1
elif judge(B_pattern, line[0]):
arr[1] += 1
elif judge(C_pattern, line[0]):
arr[2] += 1
elif judge(D_pattern, line[0]):
arr[3] += 1
elif judge(E_pattern, line[0]):
arr[4] += 1
elif judge(escape, line[0]):
continue
else:
arr[5] += 1 #IP地址错误
else: #掩码错误
arr[5] += 1
except:
print(' '.join([str(i) for i in arr])) #输出
break
HJ19 简单错误记录
描述
开发一个简单错误记录功能小模块,能够记录出错的代码所在的文件名称和行号。
处理:
1、 记录最多8条错误记录,循环记录,最后只用输出最后出现的八条错误记录。对相同的错误记录只记录一条,但是**错误计数增加。最后一个斜杠后面的带后缀名的部分(保留最后16位)和行号完全匹配的记录才做算是****“相同”**的错误记录。
2、 超过16个字符的文件名称,只记录文件的最后有效16个字符;
3、 输入的文件可能带路径,记录文件名称不能带路径。也就是说,哪怕不同路径下的文件,如果它们的名字的后16个字符相同,也被视为相同的错误记录
4、循环记录时,只以第一次出现的顺序为准,后面重复的不会更新它的出现时间,仍以第一次为准
数据范围:错误记录数量满足 1≤n≤100 ,每条记录长度满足 1 ≤len≤100
输入描述:
每组只包含一个测试用例。一个测试用例包含一行或多行字符串。每行包括带路径文件名称,行号,以空格隔开。
输出描述:
将所有的记录统计并将结果输出,格式:文件名 代码行数 数目,一个空格隔开,如:
方法一:暴力法
#include<iostream>
#include<vector>
using namespace std;
string getfilename(string filepath){ //题取文件名
string res = "";
for(int i = filepath.length() - 1; i >= 0; i--){ //逆向查找到第一个斜杠
if(filepath[i] == '\\')
break;
res = filepath[i] + res; //将字符加到字符串前面
}
if(res.length() > 16) //长度大于16的时候,截取后16位
res = res.substr(res.length() - 16, 16);
return res;
}
bool find(vector<pair<pair<string, int>, int>>& record, string& file, int num){ //找到出现过的文件名和行号
for(int i = 0; i < record.size(); i++){
if(record[i].first.first == file && record[i].first.second == num){ //文件名和行号相同
record[i].second++; //直接在后面添加出现次数
return true;
}
}
return false;
}
void findoutput(vector<pair<pair<string, int>, int>>& record, string& file, int num){ //打印该错误出现的次数
for(int i = 0; i < record.size(); i++){
if(record[i].first.first == file && record[i].first.second == num){ //文件名和行号相同
cout << record[i].second << endl; //直接输出次数
return;
}
}
}
int main(){
string filepath;
int num;
vector<pair<pair<string, int>, int> > record; //记录文件名、行号、出现次数
vector<pair<string, int> > res(8, {"", 0});
int index = 0; //记录下标
while(cin >> filepath >> num){
string file = getfilename(filepath); //提取文件名
if(!find(record, file, num)){ //出现新的才添加
record.push_back(make_pair(make_pair(file, num), 1)); //记录中添加一个全新的
res[index] = make_pair(file, num);
index = (index + 1) % 8; //循环
}
}
for(int i = 0; i < 8; i++){
if(res[index].first != ""){ //只输出有记录的,防止不足8个
cout << res[index].first << " " << res[index].second << " ";
findoutput(record, res[index].first, res[index].second);
}
index = (index + 1) % 8;
}
return 0;
}
方法二:哈希表

#include<iostream>
#include<vector>
#include<unordered_map>
using namespace std;
string getfilename(string filepath){ //题取文件名
string res = "";
for(int i = filepath.length() - 1; i >= 0; i--){ //逆向查找到第一个斜杠
if(filepath[i] == '\\')
break;
res = filepath[i] + res; //将字符加到字符串前面
}
if(res.length() > 16) //长度大于16的时候,截取后16位
res = res.substr(res.length() - 16, 16);
return res;
}
int main(){
string filepath, num; //把路径和行号都当成字符串
unordered_map<string, int> mp;
vector<string> res(8, "");
int index = 0; //记录下标
while(cin >> filepath >> num){
string file = getfilename(filepath);
string key = file + " " + num;
if(mp.find(key) == mp.end()){ //没有出现过,需要添加到哈希表中
mp[key] = 1;
res[index] = key;
index = (index + 1) % 8; //循环记录
}else
mp[key]++; //遇到相同的错误,计数增加
}
for(int i = 0; i < 8; i++){
if(res[index] != "") //只输出有记录的,防止不足8个
cout << res[index] << " " << mp[res[index]] << endl;
index = (index + 1) % 8;
}
return 0;
}
HJ20 密码验证合格程序
描述
密码要求:
1.长度超过8位
2.包括大小写字母.数字.其它符号,以上四种至少三种
3.不能有长度大于2的不含公共元素的子串重复 (注:其他符号不含空格或换行)
数据范围:输入的字符串长度满足 1≤n≤100
输入描述:
一组字符串。
输出描述:
如果符合要求输出:OK,否则输出NG
方法一:暴力验证

#include<iostream>
#include<string>
using namespace std;
int main(){
string s;
while(cin >> s){
if(s.length() <= 8){ //长度不超过不可行
cout << "NG" << endl;
continue;
}
int flag[4] = {0};
for(int i = 0; i < s.length(); i++){
if(s[i] >= 'A' && s[i] <= 'Z') //大写字母
flag[0] = 1;
else if(s[i] >= 'a' && s[i] <= 'z') //小写字母
flag[1] = 1;
else if(s[i] >= '0' && s[i] <= '9') //数字
flag[2] = 1;
else //其他符号
flag[3] = 1;
}
if(flag[0] + flag[1] + flag[2] + flag[3] < 3){ //符号少于三种
cout << "NG" << endl;
continue;
}
bool repute = false; //记录重复子串
for(int i = 0; i <= s.length() - 6; i++) //遍历检查是否有长度为3的相同的字串
for(int j = i + 3; j < s.length(); j++)
if(s.substr(i, 3) == s.substr(j, 3)){
repute = true;
break;
}
if(repute) //有重复
cout << "NG" << endl;
else
cout << "OK" << endl;
}
return 0;
}
方法二:正则表达式
#include<iostream>
#include<string>
#include<regex>
using namespace std;
int main(){
string s;
while(cin >> s){
if(s.length() <= 8){ //长度不超过不可行
cout << "NG" << endl;
continue;
}
string re[4] = { "[a-z]", "[A-Z]", "\\d", "[^a-zA-Z0-9]" }; //分别匹配小写字母、大写字母、数字、其他字符
int count = 0;
for (int i = 0; i < 4; i++) {
regex pattern(re[i]);
if (regex_search(s, pattern)) //只需要查找到,不要求完全匹配
count++;
}
if(count < 3){ //符号少于三种
cout << "NG" << endl;
continue;
}
regex pattern(".*(...)(.*\\1).*"); //匹配串前后连续3个字符一样的
if(regex_search(s, pattern))
cout << "NG" << endl;
else
cout << "OK" << endl;
}
return 0;
}
HJ21 简单密码
描述
现在有一种密码变换算法。
九键手机键盘上的数字与字母的对应: 1--1, abc--2, def--3, ghi--4, jkl--5, mno--6, pqrs--7, tuv--8 wxyz--9, 0--0,把密码中出现的小写字母都变成九键键盘对应的数字,如:a 变成 2,x 变成 9.
而密码中出现的大写字母则变成小写之后往后移一位,如:X ,先变成小写,再往后移一位,变成了 y ,例外:Z 往后移是 a 。
数字和其它的符号都不做变换。
数据范围: 输入的字符串长度满足 1≤n≤100
输入描述:
输入一组密码,长度不超过100个字符。
输出描述:
输出密码变换后的字符串
方法一:查表法

#include<iostream>
#include<string>
using namespace std;
const string dict1="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";//解密前
const string dict2="bcdefghijklmnopqrstuvwxyza22233344455566677778889999";//解密后
int main(){
string str;
while(getline(cin,str)){//逐行输入
for(int i=0;i<str.size();i++){//遍历一遍字符串
for(int j=0;j<dict1.size();j++){//在dict1中找到对应的位置
if(dict1[j]==str[i]){//替换为dict2中的相同位置的字符
str[i]=dict2[j];
break;
}
}
}
cout<<str<<endl;
}
return 0;
}
方法二:遍历发
#include<iostream>
using namespace std;
int main(){
string str;
while(cin>>str){
for(int i=0;i<str.size();i++){
if(str[i]>='A' && str[i]<'Z'){//大写字母变成小写字母后移一位
str[i] = str[i] + 33;
}
else if(str[i] == 'Z'){
str[i] = 'a';
}else if(str[i]>='a' && str[i]<='c'){//abc--2
str[i] = '2';
}else if(str[i]>='d' && str[i]<='f'){//def--3
str[i] = '3';
}else if(str[i]>='g' && str[i]<='i'){//ghi--4
str[i] = '4';
}else if(str[i]>='j' && str[i]<='l'){//jkl--5
str[i] = '5';
}else if(str[i]>='m' && str[i]<='o'){//mno--6
str[i] = '6';
}else if(str[i]>='p' && str[i]<='s'){//pqrs--7
str[i] = '7';
}else if(str[i]>='t' && str[i]<='v'){//tuv--8
str[i] = '8';
}else if(str[i]>='w' && str[i]<='z'){//wxyz--9
str[i] = '9';
}
}
cout<<str<<endl;
return 0;
}
}
HJ22 汽水瓶
描述
某商店规定:三个空汽水瓶可以换一瓶汽水,允许向老板借空汽水瓶(但是必须要归还)。
小张手上有n个空汽水瓶,她想知道自己最多可以喝到多少瓶汽水。
数据范围:输入的正整数满足 1 \le n \le 100 \1≤n≤100
注意:本题存在多组输入。输入的 0 表示输入结束,并不用输出结果。
输入描述:
输入文件最多包含 10 组测试数据,每个数据占一行,仅包含一个正整数 n( 1<=n<=100 ),表示小张手上的空汽水瓶数。n=0 表示输入结束,你的程序不应当处理这一行。
输出描述:
对于每组测试数据,输出一行,表示最多可以喝的汽水瓶数。如果一瓶也喝不到,输出0。
方法一:递归

#include<iostream>
using namespace std;
int recursion(int n){
if(n == 1) //只剩1个空瓶,没办法喝到
return 0;
if(n == 2) //剩2个空瓶,可以喝一瓶
return 1;
return recursion(n - 2) + 1; //减去三个空瓶得到可以喝一瓶,之后得到一个空瓶
}
int main(){
int n;
while(cin >> n){
if(n == 0) //0表示结束
break;
cout << recursion(n) << endl; //递归处理
}
return 0;
}
方法二:迭代
#include<iostream>
using namespace std;
int main(){
int n;
while(cin >> n){
if(n == 0) //0表示结束
break;
int count = 0;
while(n > 2){
count++;
n -= 2; //每次两个空瓶换一瓶汽水
}
//检查最后剩余
if(n == 2)
cout << ++count << endl;
else
cout << count << endl;
}
return 0;
}
方法三:数学规律
#include<iostream>
using namespace std;
int main(){
int n;
while(cin >> n){
if(n == 0) //0表示结束
break;
cout << n / 2 << endl; //直接输出n/2
}
return 0;
}
HJ23 删除字符串中出现次数最少的字符
描述
实现删除字符串中出现次数最少的字符,若出现次数最少的字符有多个,则把出现次数最少的字符都删除。输出删除这些单词后的字符串,字符串中其它字符保持原来的顺序。
数据范围:输入的字符串长度满足 1≤n≤20 ,保证输入的字符串中仅出现小写字母
输入描述:
字符串只包含小写英文字母, 不考虑非法输入,输入的字符串长度小于等于20个字节。
输出描述:
删除字符串中出现次数最少的字符后的字符串。
方法一:暴力解法
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
bool comp(pair<char, int>& a, pair<char, int>& b){ //重载比较
return a.second < b.second;
}
int main(){
string s;
while(cin >> s){
vector<pair<char, int> > record;
for(int i = 0; i < s.length(); i++){
int j = 0;
for(; j < record.size(); j++) //遍历记录数组
if(record[j].first == s[i]){ //要是出现过
record[j].second++; //直接添加次数
break;
}
if(j == record.size()) //否则push新的字符
record.push_back(make_pair(s[i], 1));
}
sort(record.begin(), record.end(), comp); //对出现次数排序
int minindex = record.size();
for(int i = 1; i < record.size(); i++){
if(record[i].second > record[0].second){ //找到第一个不是最少次数的下标
minindex = i;
break;
}
}
for(int i = 0; i < s.length(); i++){
bool flag = false;
for(int j = 0; j < minindex; j++){ //遍历所有的最少次数
if(s[i] == record[j].first){ //检查s[i]是否在其中
flag = true;
break;
}
}
if(!flag) //不在其中则输出
cout << s[i];
}
cout << endl;
}
return 0;
}
方法二:哈希
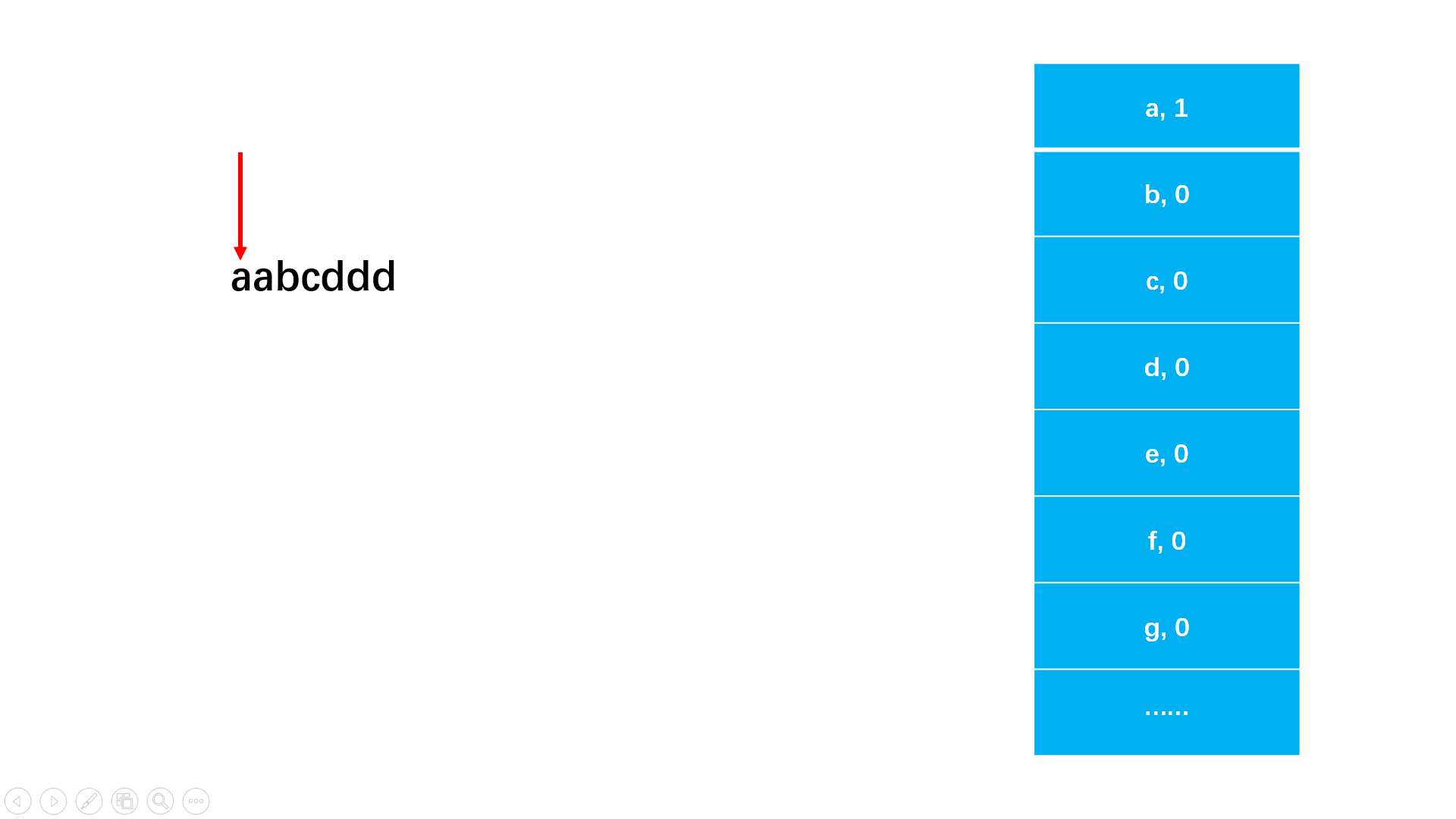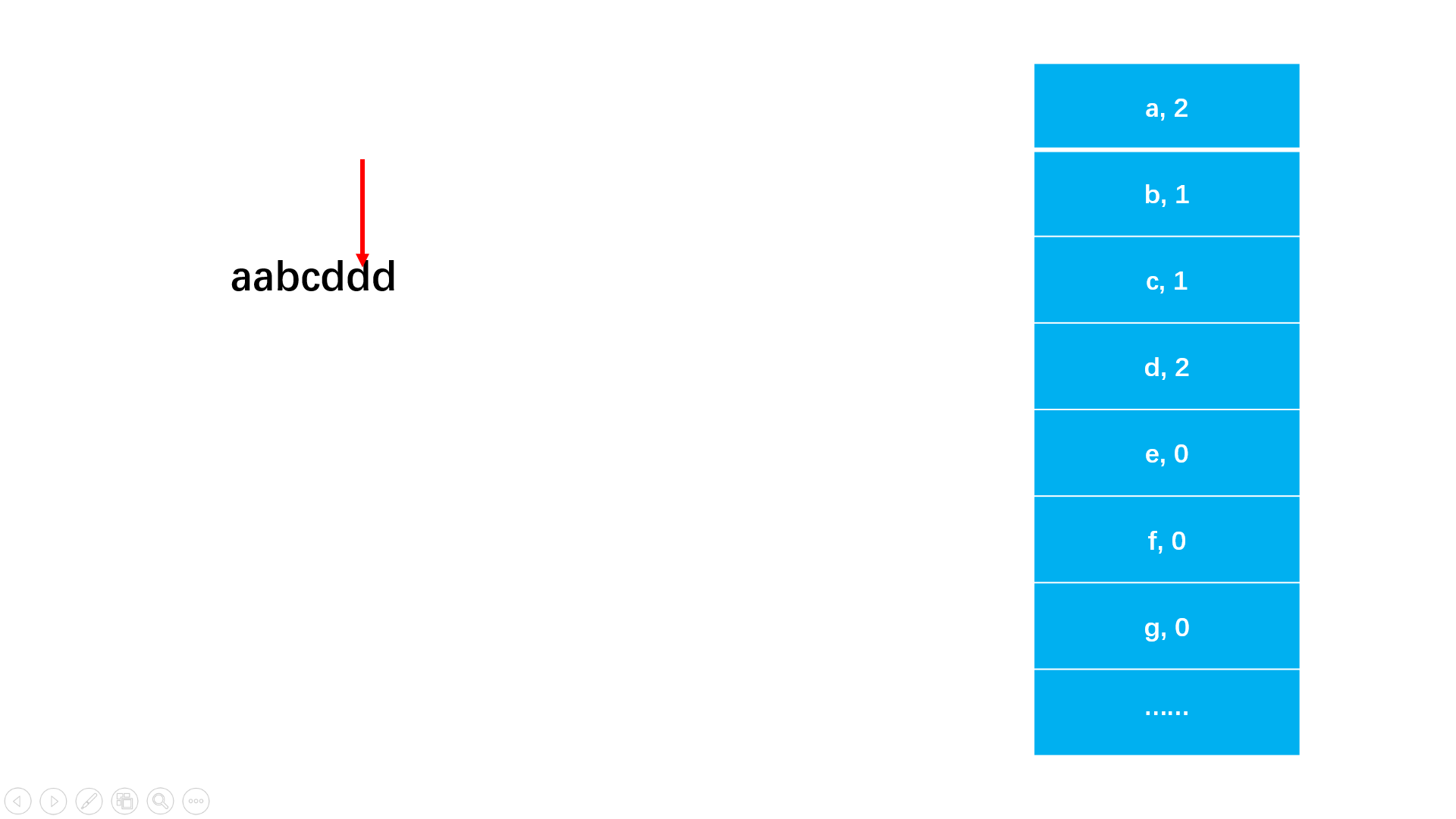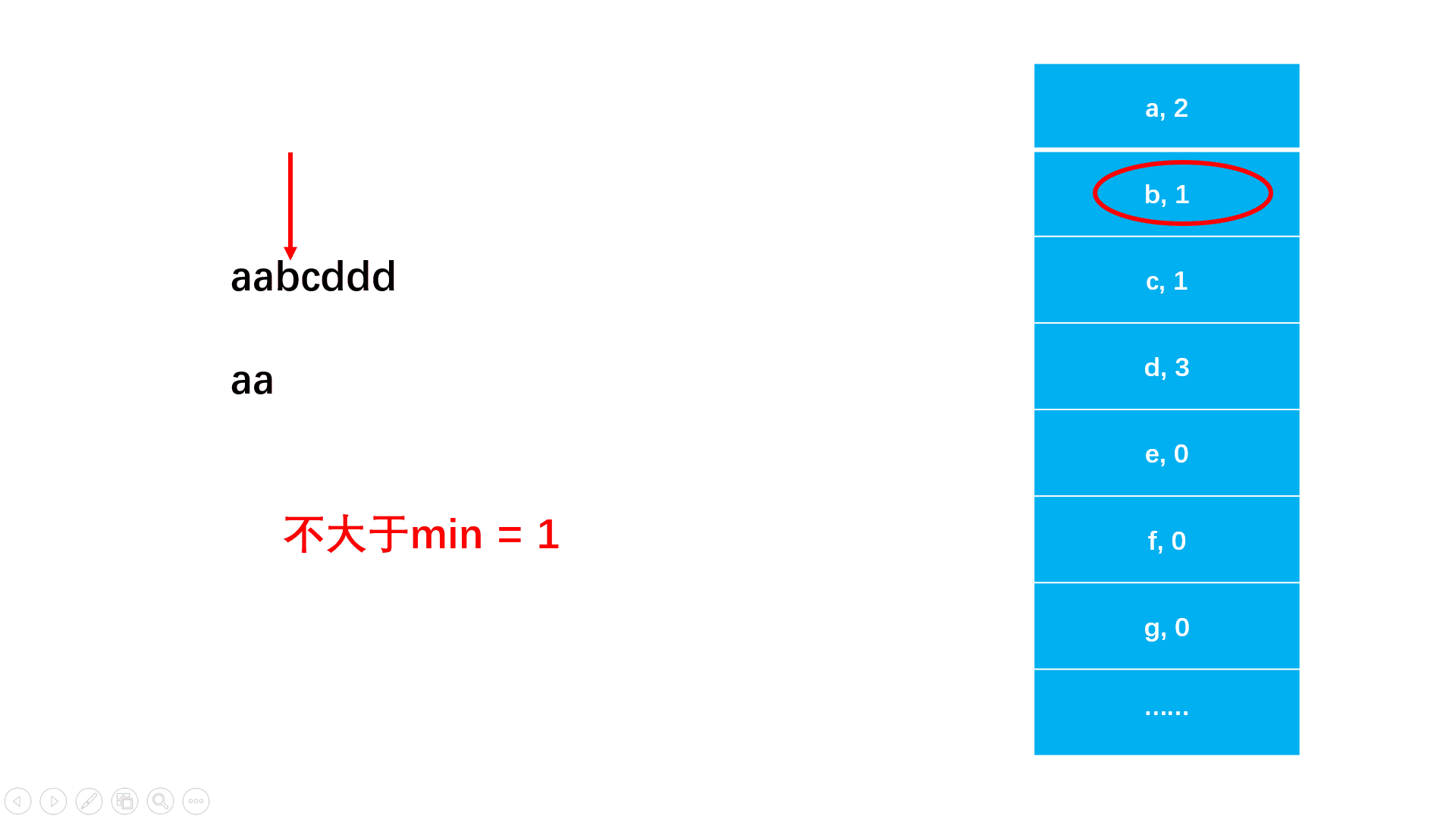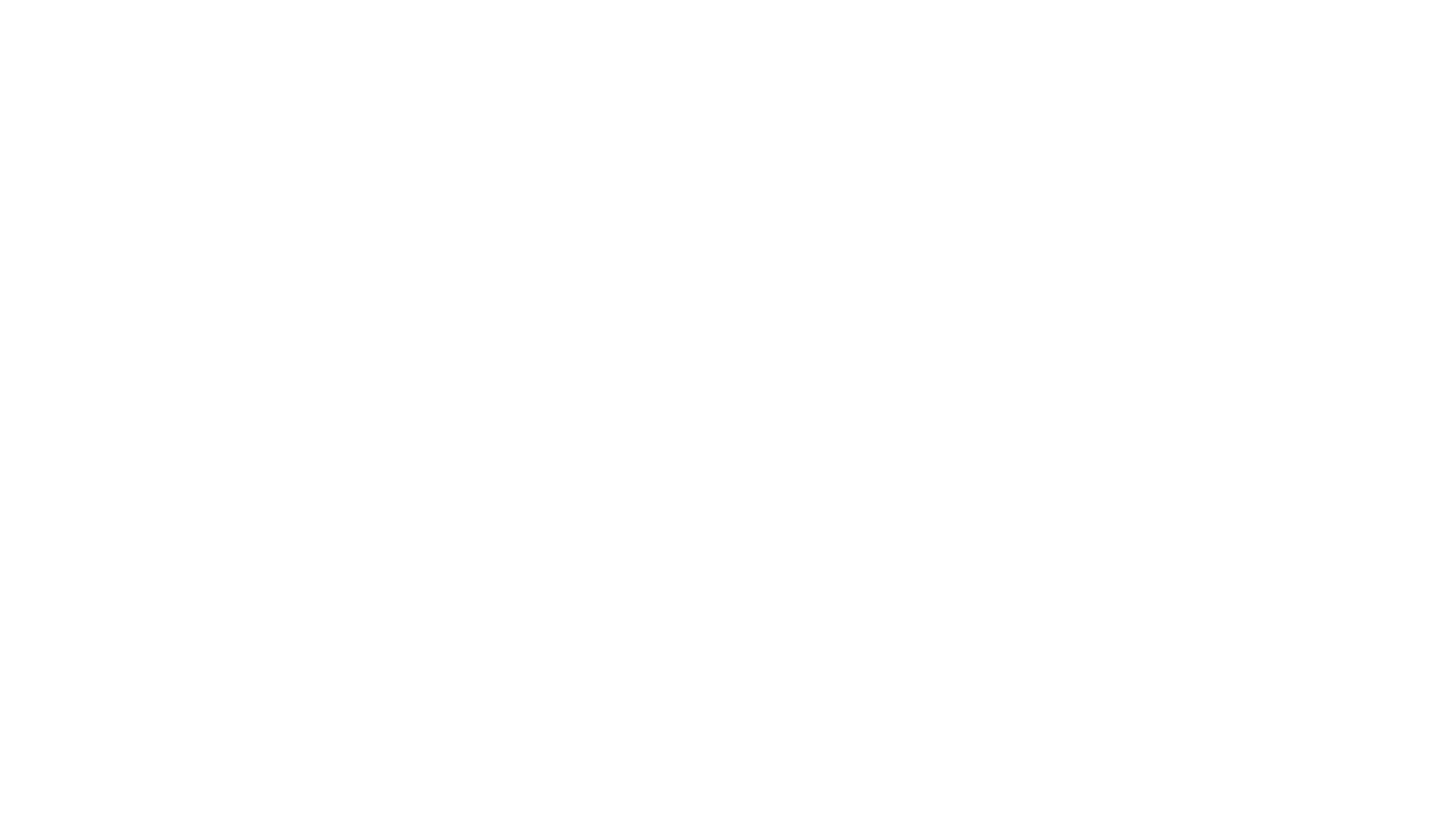
#include<iostream>
#include<vector>
#include<string>
using namespace std;
int main(){
string s;
while(cin >> s){
vector<int> count(26, 0); //记录字母出现的次数
for(int i = 0; i < s.length(); i++) //遍历字符串
count[s[i] - 'a']++; //统计每个字母出现的次数
int min = count[s[0] - 'a']; //以第一个出现的字符为始
for(int i = 0; i < 26; i++)
if(min > count[i] && count[i] > 0) //一定要找到最小但不是0的次数
min = count[i];
for(int i = 0; i < s.length(); i++) //输出所有出现次数大于min的字符
if(count[s[i] - 'a'] > min)
cout << s[i];
cout << endl;
}
return 0;
}
HJ24 合唱队

输入描述:
用例两行数据,第一行是同学的总数 N ,第二行是 N 位同学的身高,以空格隔开
输出描述:
最少需要几位同学出列
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(){
int n, tmp;
int i, j;
vector<int> heights;
// 输入
while(cin >> n){
for(i = 0; i < n; i++){
cin >> tmp;
heights.push_back(tmp);
}
// 设置两个dp数组
vector<int> dp_h(n, 1), dp_t(n, 1);
// 正序遍历
for(i = 0; i < n; i++){
for(j = 0; j < i; j++){
if(heights[i] > heights[j]){
dp_h[i] = max(dp_h[i], dp_h[j] + 1);
}
}
}
// 逆序遍历
for(i = n-1; i >= 0; i--){
for(j = n-1; j > i; j--){
if(heights[i] > heights[j]){
dp_t[i] = max(dp_t[i], dp_t[j] + 1);
}
}
}
// 求和得到最长先增后减子序列的长度
int maxNum = 0;
for(i = 0; i < n; i++){
if(dp_t[i] + dp_h[i] - 1 > maxNum)
maxNum = dp_t[i] + dp_h[i] - 1;
}
// 输出
cout << n - maxNum << endl;
// 清除vector,以供下一轮使用
heights.clear();
}
return 0;
}
优化解法:辅助数组 + 二分法

#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(){
int n, tmp;
int i, j;
vector<int> heights;
// 输入
while(cin >> n){
for(i = 0; i < n; i++){
cin >> tmp;
heights.push_back(tmp);
}
// 设置两个dp数组
vector<int> dp_h(n), dp_t(n);
// 设置cache数组
vector<int> cache;
// 正序遍历
for(i = 0; i < n; i++){
// 在当前cache中找到最小的大于等于当前值的元素的下标
// 其中,lower_bound()函数是定义在algorithm头文件中的二分查找函数
int potIndex = lower_bound(cache.begin(), cache.end(), heights[i]) - cache.begin();
dp_h[i] = potIndex + 1;
/*
lower_bound()函数如果找不到比当前值小的元素时,返回end()迭代器
此时potIndex变量的值将大于cache的大小。
即此处表示能在cache中找到大于等于当前值的元素
对其进行更新,用当前值(<= cache[potIndex])替换cache[potIndex]
由于我们只需要找到一个最长的子序列就可以,所以我们要保证cache中的元素尽量小
较小的元素能够在效果上代表更大的值
*/
if(potIndex < cache.size())
cache[potIndex] = heights[i];
else
cache.push_back(heights[i]);
}
cache.clear();
// 逆序遍历
for(i = n-1; i >= 0; i--){
int potIndex = lower_bound(cache.begin(), cache.end(), heights[i]) - cache.begin();
dp_t[i] = potIndex + 1;
if(potIndex < cache.size())
cache[potIndex] = heights[i];
else
cache.push_back(heights[i]);
}
// 求和得到最长先增后减子序列的长度
int maxNum = 0;
for(i = 0; i < n; i++){
if(dp_t[i] + dp_h[i] - 1 > maxNum)
maxNum = dp_t[i] + dp_h[i] - 1;
}
// 输出
cout << n - maxNum << endl;
// 清除vector,以供下一轮使用
heights.clear();
}
return 0;
}
HJ25 数据分类处理
描述
信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。
采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出。
数据范围:1≤I,R≤100 ,输入的整数大小满足 0≤val≤231−1
输入描述:
一组输入整数序列I和一组规则整数序列R,I和R序列的第一个整数为序列的个数(个数不包含第一个整数);整数范围为0~(2^31)-1,序列个数不限
输出描述:
从R依次中取出Ri,对I进行处理,找到满足条件的I:
I整数对应的数字需要连续包含Ri对应的数字。比如Ri为23,I为231,那么I包含了Ri,条件满足 。
按Ri从小到大的顺序:
(1)先输出Ri;
(2)再输出满足条件的I的个数;
(3)然后输出满足条件的I在I序列中的位置索引(从0开始);
(4)最后再输出I。
附加条件:
(1)Ri需要从小到大排序。相同的Ri只需要输出索引小的以及满足条件的I,索引大的需要过滤掉
(2)如果没有满足条件的I,对应的Ri不用输出
(3)最后需要在输出序列的第一个整数位置记录后续整数序列的个数(不包含“个数”本身)
序列I:15,123,456,786,453,46,7,5,3,665,453456,745,456,786,453,123(第一个15表明后续有15个整数)
序列R:5,6,3,6,3,0(第一个5表明后续有5个整数)
输出:30, 3,6,0,123,3,453,7,3,9,453456,13,453,14,123,6,7,1,456,2,786,4,46,8,665,9,453456,11,456,12,786
说明:
30----后续有30个整数
3----从小到大排序,第一个Ri为0,但没有满足条件的I,不输出0,而下一个Ri是3
6--- 存在6个包含3的I
0--- 123所在的原序号为0
123--- 123包含3,满足条件
方法一:排序+暴力验证
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
bool check(int r, int i){//检查数字i包含数字r
if(r > i) //i比r还小,不可能
return false;
int top = 1;
while(r / top != 0) //记录每次要连续除10的多少次方,余数才能和r比较
top *= 10;
if(r == 0)
top = 10;
int k = 0;
while(i * 10 / top != 0){ //连除比较
if((i % top) == r)
return true;
i /= 10;
}
return false;
}
int main(){
int n, m; //记录序列I和序列R的大小
while(cin >> n){
vector<int> I(n);
for(int i = 0; i < n; i++)
cin >> I[i]; //输入n个整数序列I
cin >> m; //整数序列R的长度
vector<int> R(m);
for(int i = 0; i < m; i++) //输入m个整数序列R
cin >> R[i];
sort(R.begin(), R.end()); //排序
vector<int> res;
for(int i = 0; i < m; i++){
if(i != 0 && R[i] == R[i - 1]) //去重
continue;
int count = 0;
vector<int> index; //记录符合条件的下标
for(int j = 0; j < n; j++){
if(check(R[i], I[j])){
count++;
index.push_back(j);
}
}
if(count != 0){ //如果有出现连续的R[i],添加头部的R[i]及后面有多少个数中出现了
res.push_back(R[i]);
res.push_back(count);
for(int j = 0; j < index.size(); j++){
res.push_back(index[j]);
res.push_back(I[index[j]]);
}
}
}
cout << res.size(); //先输出个数
for(int i = 0; i < res.size(); i++) //再逐个输出
cout << " " << res[i];
cout << endl;
}
return 0;
}
方法二:哈希表+字符串

#include<iostream>
#include<vector>
#include<algorithm>
#include<map>
using namespace std;
int main(){
int n, m; //记录序列I和序列R的大小
while(cin >> n){
vector<int> I(n);
for(int i = 0; i < n; i++)
cin >> I[i]; //输入n个整数序列I
cin >> m; //整数序列R的长度
map<int, int> R;
for(int i = 0; i < m; i++){ //哈希表记录序列R,直接去重加排序
int t;
cin >> t;
R[t] = 1;
}
int total = 0;
string res = ""; //以字符串的形式输出
for(auto iter = R.begin(); iter != R.end(); iter++){
int count = 0;
string temp = ""; //记录这一轮的R[i]有多少匹配的
for(int i = 0; i < n; i++){
if(to_string(I[i]).find(to_string(iter->first)) != string::npos){ //找到出现数字
count++; //数量加1
temp += to_string(i) + ' ' + to_string(I[i]) + ' '; //添加索引和该数字
}
}
if(count != 0){ //如果有出现连续的R[i],添加头部的R[i]及后面有多少个数中出现了
res += to_string(iter->first) + ' ' + to_string(count) + ' ' + temp;
total += (2 * count + 2); //补充后面增加了多少数
}
}
res = to_string(total) + ' ' + res; //添加总个数
cout << res << endl;
}
return 0;
}
HJ26 字符串排序
描述
编写一个程序,将输入字符串中的字符按如下规则排序。
规则 1 :英文字母从 A 到 Z 排列,不区分大小写。
如,输入: Type 输出: epTy
规则 2 :同一个英文字母的大小写同时存在时,按照输入顺序排列。
如,输入: BabA 输出: aABb
规则 3 :非英文字母的其它字符保持原来的位置。
如,输入: By?e 输出: Be?y
数据范围:输入的字符串长度满足1≤n≤1000
输入描述:
输入字符串
输出描述:
输出字符串
方法一:冒泡排序
#include<iostream>
#include<string>
using namespace std;
bool ischar(char c){ //判断是否是字符
return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z');
}
int toint(char c){ //将大小写字母转为同样的数字起跑线
return (c >= 'a' && c <= 'z') ? c - 'a' : c - 'A';
}
int main(){
string s;
while(getline(cin, s)){
int next;
for(int i = s.length() - 1; i > 0; i--){
for(int j = 0; j < i; j++){
if(ischar(s[j])){ //首先要是字母才可以交换位置
next = j + 1;
while(next <= i && !ischar(s[next]))
next++; //找到下一个字母
if(ischar(s[next]) && toint(s[j]) > toint(s[next])){
swap(s[j], s[next]); //交换
}
}
}
}
cout << s <<endl;
}
return 0;
}
方法二:桶排序思想
#include<iostream>
#include<string>
#include<vector>
using namespace std;
int main(){
string s;
while(getline(cin, s)){
vector<vector<char> > table(26);
vector<int> index(s.length(), -1);
for(int i = 0; i < s.length(); i++){
if(s[i] >= 'a' && s[i] <= 'z'){ //小写
index[i] = s[i] - 'a'; //记录这是哪一个字母索引
table[s[i] - 'a'].push_back(s[i]); //将字母加入桶中
}
if(s[i] >= 'A' && s[i] <= 'Z'){ // 大写
index[i] = s[i] - 'A'; //记录这是哪一个字母索引
table[s[i] - 'A'].push_back(s[i]); //将字母加入桶中
}
}
int x = 0, y = 0; //table数组的下标
for(int i = 0; i < index.size(); i++){
if(index[i] != -1){
while(y == table[x].size()){ //跳过为0的桶
x++;
y = 0;
}
s[i] = table[x][y]; //每次加入一个桶中元素
y++;
}
}
cout << s <<endl;
}
return 0;
}
HJ27 查找兄弟单词
描述
定义一个单词的“兄弟单词”为:交换该单词字母顺序(注:可以交换任意次),而不添加、删除、修改原有的字母就能生成的单词。
兄弟单词要求和原来的单词不同。例如: ab 和 ba 是兄弟单词。 ab 和 ab 则不是兄弟单词。
现在给定你 n 个单词,另外再给你一个单词 x ,让你寻找 x 的兄弟单词里,按字典序排列后的第 k 个单词是什么?
注意:字典中可能有重复单词。
数据范围:1 ≤n≤1000 ,输入的字符串长度满足 1≤len(str)≤10 ,1≤k<n;
输入描述:
输入只有一行。 先输入字典中单词的个数n,再输入n个单词作为字典单词。 然后输入一个单词x 最后后输入一个整数k
输出描述:
第一行输出查找到x的兄弟单词的个数m 第二行输出查找到的按照字典顺序排序后的第k个兄弟单词,没有符合第k个的话则不用输出。
方法一:排序判断
#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
bool isbrother(string s1, string s2){ //查看是否是兄弟单词
if(s1.length() == s2.length()){ //兄弟单词一定要长度相等
if(s1 == s2) //不能是同一个
return false;
sort(s1.begin(), s1.end()); //对两个字符串按字符字典序排序
sort(s2.begin(), s2.end());
if(s1 == s2) //排序后一样才是改变位置能办到的
return true;
}
return false;
}
int main(){
int n;
while(cin >> n){
vector<string> strs(n);
for(int i = 0; i < n; i++) //输入n个字符串
cin >> strs[i];
string str;
cin >> str; //字符串str
int k;
cin >> k;
vector<string> brothers;
for(int i = 0; i < n; i++){ //检查每个字符串是否是兄弟单词
if(isbrother(str, strs[i]))
brothers.push_back(strs[i]);
}
sort(brothers.begin(), brothers.end()); //对后续排序
cout << brothers.size() << endl;
if(brothers.size() >= k) //输出第k个
cout << brothers[k - 1] << endl;
}
return 0;
}
方法二:哈希表判断

#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
#include<unordered_map>
using namespace std;
bool isbrother(string s1, string s2){
if(s1.length() == s2.length()){ //兄弟单词一定要长度相等
if(s1 == s2) //不能是同一个
return false;
unordered_map<char, int> mp1;
unordered_map<char, int> mp2;
for(int i = 0; i < s1.length(); i++) //将字符串1的所有字符加入哈希表1中统计出现次数
mp1[s1[i]]++;
for(int i = 0; i < s2.length(); i++) //将字符串2的所有字符加入哈希表2中统计出现次数
mp2[s2[i]]++;
auto it = mp1.begin();
while(it != mp1.end()){ //遍历哈希表1
if(mp2.find(it->first) == mp2.end() || mp2[it->first] != it->second){ //在哈希表2中找到表1遍历到的字符且查看value是否一样
return false;
}
it++;
}
return true;
}
return false;
}
int main(){
int n;
while(cin >> n){
vector<string> strs(n);
for(int i = 0; i < n; i++) //输入n个字符串
cin >> strs[i];
string str;
cin >> str; //字符串str
int k;
cin >> k;
vector<string> brothers;
for(int i = 0; i < n; i++){ //检查每个字符串是否是兄弟单词
if(isbrother(str, strs[i]))
brothers.push_back(strs[i]);
}
sort(brothers.begin(), brothers.end()); //对后续排序
cout << brothers.size() << endl;
if(brothers.size() >= k) //输出第k个
cout << brothers[k - 1] << endl;
}
return 0;
}
HJ28 素数伴侣
描述
题目描述
若两个正整数的和为素数,则这两个正整数称之为“素数伴侣”,如2和5、6和13,它们能应用于通信加密。现在密码学会请你设计一个程序,从已有的 N ( N 为偶数)个正整数中挑选出若干对组成“素数伴侣”,挑选方案多种多样,例如有4个正整数:2,5,6,13,如果将5和6分为一组中只能得到一组“素数伴侣”,而将2和5、6和13编组将得到两组“素数伴侣”,能组成“素数伴侣”最多的方案称为“最佳方案”,当然密码学会希望你寻找出“最佳方案”。
输入:
有一个正偶数 n ,表示待挑选的自然数的个数。后面给出 n 个具体的数字。
输出:
输出一个整数 K ,表示你求得的“最佳方案”组成“素数伴侣”的对数。
数据范围: 1≤n≤100 ,输入的数据大小满足 2≤val≤30000
输入描述:
输入说明
1 输入一个正偶数 n
2 输入 n 个整数
输出描述:
求得的“最佳方案”组成“素数伴侣”的对数。
方法一:暴力匈牙利算法


#include<iostream>
#include<vector>
using namespace std;
bool isprime(int num){ //判断一个数是否是素数
for(int i = 2; i * i <= num; i++){ //遍历到根号num
if(num % i == 0) //检查有无余数
return false;
}
return true;
}
bool find(int num, vector<int>& evens, vector<bool>& used, vector<int>& match){
for(int i = 0; i < evens.size(); i++){ //遍历每个偶数与奇数比较
if(isprime(num + evens[i]) && !used[i]){
used[i] = true;
if(match[i] == 0 || find(match[i], evens, used, match)){ //如果第i个偶数还未配对,或者跟它配对的奇数还有别的选择
match[i] = num; //则配对该数
return true;
}
}
}
return false;
}
int main(){
int n;
while(cin >> n){
vector<int> odds;
vector<int> evens;
vector<int> nums(n);
for(int i = 0; i < n; i++){ //输入n个数
cin >> nums[i];
if(nums[i] % 2) //奇数
odds.push_back(nums[i]);
else //偶数
evens.push_back(nums[i]);
}
int count = 0;
if(odds.size() == 0 || evens.size() == 0){ //缺少奇数或者偶数无法构成素数
cout << count << endl;
continue;
}
vector<int> match(evens.size(), 0); //统计每个偶数的配对是哪个奇数
for(int i = 0; i < odds.size(); i++){ //遍历每个奇数
vector<bool> used(evens.size(), false); //每一轮偶数都没用过
if(find(odds[i], evens, used, match)) //能否找到配对的偶数,且要最优
count++;
}
cout << count << endl;
}
return 0;
}
方法二:哈希表优化匈牙利算法
#include<iostream>
#include<vector>
using namespace std;
bool isprime(int num){ //判断一个数是否是素数
for(int i = 2; i * i <= num; i++){ //遍历到根号num
if(num % i == 0) //检查有无余数
return false;
}
return true;
}
bool find(int index, vector<bool>& used, vector<int>& match, vector<vector<bool>>& map){
for(int i = 0; i < used.size(); i++){ //遍历每个偶数与奇数比较
if(map[i][index] && !used[i]){ //直接查询能否构成
used[i] = true;
if(match[i] == -1 || find(match[i], used, match, map)){ //如果第i个偶数还未配对,或者跟它配对的奇数还有别的选择
match[i] = index; //则配对该数
return true;
}
}
}
return false;
}
int main(){
int n;
while(cin >> n){
vector<int> odds;
vector<int> evens;
vector<int> nums(n);
for(int i = 0; i < n; i++){ //输入n个数
cin >> nums[i];
if(nums[i] % 2) //奇数
odds.push_back(nums[i]);
else //偶数
evens.push_back(nums[i]);
}
int count = 0;
if(odds.size() == 0 || evens.size() == 0){ //缺少奇数或者偶数无法构成素数
cout << count << endl;
continue;
}
vector<vector<bool>> map(evens.size(), vector<bool>(odds.size(), false));
for(int i = 0; i < evens.size(); i++){ //构建所有能能够相连的奇数偶数的边
for(int j = 0; j < odds.size(); j++){
if(isprime(evens[i] + odds[j]))
map[i][j] = true;
}
}
vector<int> match(evens.size(), -1); //统计每个偶数的配对是哪个奇数
for(int i = 0; i < odds.size(); i++){ //遍历每个奇数
vector<bool> used(evens.size(), false); //每一轮偶数都没用过
if(find(i, used, match, map)) //能否找到配对的偶数,且要最优,不传数,传下标
count++;
}
cout << count << endl;
}
return 0;
}
HJ29 字符串加解密
描述
对输入的字符串进行加解密,并输出。
加密方法为:
当内容是英文字母时则用该英文字母的后一个字母替换,同时字母变换大小写,如字母a时则替换为B;字母Z时则替换为a;
当内容是数字时则把该数字加1,如0替换1,1替换2,9替换0;
其他字符不做变化。
解密方法为加密的逆过程。
数据范围:输入的两个字符串长度满足 1≤n≤1000 ,保证输入的字符串都是只由大小写字母或者数字组成
输入描述:
第一行输入一串要加密的密码
第二行输入一串加过密的密码
输出描述:
第一行输出加密后的字符
第二行输出解密后的字符
方法一:

#include<iostream>
#include<string>
using namespace std;
void encoder(string str)
{
for(int i=0;i<str.size();i++)
{
if(isalpha(str[i])){//英文字母
if(str[i]>='a'&&str[i]<='z'){//小写字母
if(str[i]=='z'){
str[i]='A';
}else{
str[i]=str[i]-'a'+'A'+1;//变换大小写同时用后一个字母替换
}
}else{//大写字母
if(str[i]=='Z'){
str[i]='a';
}else{
str[i]=str[i]-'A'+'a'+1;//变换大小写同时用后一个字母替换
}
}
}else{//数字
if(str[i]<'9') str[i]++;
else str[i]='0';//9变为0
}
}
cout<<str<<endl;
}
void decoder(string str)
{
for(int i=0;i<str.size();i++)
{
if(isalpha(str[i])){//英文字母
if(str[i]>='a'&&str[i]<='z'){//小写字母
if(str[i]=='a'){
str[i]='Z';
}else{
str[i]=str[i]-'a'+'A'-1;//变换大小写同时用前一个字母替换
}
}else{//大写字母
if(str[i]=='A'){
str[i]='z';
}else{
str[i]=str[i]-'A'+'a'-1;//变换大小写同时用前一个字母替换
}
}
}else{//数字
if(str[i]>'0') str[i]--;
else str[i]='9';//0变为9
}
}
cout<<str<<endl;
}
int main()
{
string str1, str2;
while(cin>>str1>>str2)
{
encoder(str1);
decoder(str2);
}
return 0;
}
方法二:查表法
#include <iostream>
#include <vector>
#include <string>
using namespace std;
string strlist1 = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";//加密前的字符list
string strlist2 = "BCDEFGHIJKLMNOPQRSTUVWXYZAbcdefghijklmnopqrstuvwxyza1234567890";//加密后的字符list,和list1一一对应
void encoder(string str)
{
for(int i=0; i<str.size(); i++)//遍历一遍字符串
{
for(int j=0; j<strlist1.size(); j++)//找到在list1中的位置
{
if(str[i] == strlist1[j])
{
str[i] = strlist2[j];//加密
break;
}
}
}
cout<<str<<endl;
}
void decoder(string str)
{
for(int i=0; i<str.size(); i++)//遍历一遍字符串
{
for(int j=0; j<strlist2.size(); j++)//找到在list2中的位置
{
if(str[i] == strlist2[j])
{
str[i] = strlist1[j];//解密
break;
}
}
}
cout<<str<<endl;
}
int main()
{
string str1, str2;
while(cin>>str1>>str2)
{
encoder(str1);//加密
decoder(str2);//解密
}
return 0;
}
HJ30 字符串合并处理
描述
按照指定规则对输入的字符串进行处理。
详细描述:
第一步:将输入的两个字符串str1和str2进行前后合并。如给定字符串 "dec" 和字符串 "fab" , 合并后生成的字符串为 "decfab"
第二步:对合并后的字符串进行排序,要求为:下标为奇数的字符和下标为偶数的字符分别从小到大排序。这里的下标的意思是字符在字符串中的位置。注意排序后在新串中仍需要保持原来的奇偶性。例如刚刚得到的字符串“decfab”,分别对下标为偶数的字符'd'、'c'、'a'和下标为奇数的字符'e'、'f'、'b'进行排序(生成 'a'、'c'、'd' 和 'b' 、'e' 、'f'),再依次分别放回原串中的偶数位和奇数位,新字符串变为“abcedf”
第三步:对排序后的字符串中的'0''9'、'A''F'和'a'~'f'字符,需要进行转换操作。
转换规则如下:
对以上需要进行转换的字符所代表的十六进制用二进制表示并倒序,然后再转换成对应的十六进制大写字符(注:字符 a~f 的十六进制对应十进制的10~15,大写同理)。
如字符 '4',其二进制为 0100 ,则翻转后为 0010 ,也就是 2 。转换后的字符为 '2'。
如字符 ‘7’,其二进制为 0111 ,则翻转后为 1110 ,对应的十进制是14,转换为十六进制的大写字母为 'E'。
如字符 'C',代表的十进制是 12 ,其二进制为 1100 ,则翻转后为 0011,也就是3。转换后的字符是 '3'。
根据这个转换规则,由第二步生成的字符串 “abcedf” 转换后会生成字符串 "5D37BF"。
数据范围:输入的字符串长度满足 1 \le n \le 100 \1≤n≤100
输入描述:
样例输入两个字符串,用空格隔开。
输出描述:
输出转化后的结果。
方法一:暴力解法

#include<iostream>
#include<string>
#include<algorithm>
#include<vector>
using namespace std;
char change(char ch){
int num = -1;
if(ch >= '0' && ch <= '9') //数字
num = ch - '0';
else if( (ch >= 'a' && ch <= 'f') || (ch >= 'A' && ch <= 'F')) //字母
num = tolower(ch) - 'a' + 10; //十六进制字母转为十进制数
if(num != -1){ //非数字或者字母num还是为-1
int bit[4]; // 16以内,4位
for(int i = 0; i < 4; i++){
bit[i] = num % 2; // 从下标0开始存,已经反转了
num /= 2;
}
num = bit[0] * 8 + bit[1] * 4 + bit[2] * 2 + bit[3] * 1; // 这个数的范围是在0-16之间,用16进制表示它
if(num <= 9 && num >= 0) //转回十六进制数的字符
ch = num + '0';
else if (num >= 10 && num <= 16)
ch = num - 10 + 'A';
}
return ch;
}
int main(){
string str1, str2;
while(cin >> str1 >> str2){
string s = str1 + str2; //两个字符串前后相连
string s1, s2; //分别记录奇数位和偶数位字符
for(int i = 0; i < s.length(); i++){
if(i % 2 == 0) //奇数位
s1 += s[i];
else //偶数位
s2 += s[i];
}
sort(s1.begin(), s1.end()); //奇数位字符排序
sort(s2.begin(), s2.end()); //偶数位字符排序
for(int i = 0, j = 0, k = 0; i < s.length(); i++){
if(i % 2 == 0)
s[i] = s1[j++]; //排序后添加到奇数位
else
s[i] = s2[k++]; //排序后添加到偶数位
}
for(int i = 0; i < s.length(); i++) //遍历字符串
s[i] = change(s[i]);
cout << s << endl;
}
return 0;
}
方法二:索引查表
#include<iostream>
#include<string>
#include<algorithm>
#include<vector>
using namespace std;
string helpstr1 = "0123456789abcdefABCDEF";
string helpstr2 = "084C2A6E195D3B7F5D3B7F";
int main(){
string str1, str2;
while(cin >> str1 >> str2){
string s = str1 + str2; //两个字符串前后相连
string s1, s2; //分别记录奇数位和偶数位字符
for(int i = 0; i < s.length(); i++){
if(i % 2 == 0) //奇数位
s1 += s[i];
else //偶数位
s2 += s[i];
}
sort(s1.begin(), s1.end()); //奇数位字符排序
sort(s2.begin(), s2.end()); //偶数位字符排序
for(int i = 0, j = 0, k = 0; i < s.length(); i++){
if(i % 2 == 0)
s[i] = s1[j++]; //排序后添加到奇数位
else
s[i] = s2[k++]; //排序后添加到偶数位
}
vector<int> index(123, -1);
for(int i = 0; i < helpstr1.length(); i++) //每个字母所在的索引
index[helpstr1[i]] = i;
for(int i = 0; i < s.length(); i++){ //遍历字符串
if(index[s[i]] != -1){ //对于存在索引,不存在索引就是初始值-1
s[i] = helpstr2[index[s[i]]]; //添加对应的字符
}
}
cout << s << endl;
}
return 0;
}




