HJ31 单词倒排
HJ31 单词倒排
描述
对字符串中的所有单词进行倒排。
说明:
1、构成单词的字符只有26个大写或小写英文字母;
2、非构成单词的字符均视为单词间隔符;
3、要求倒排后的单词间隔符以一个空格表示;如果原字符串中相邻单词间有多个间隔符时,倒排转换后也只允许出现一个空格间隔符;
4、每个单词最长20个字母;
数据范围:字符串长度满足 1≤n≤10000
输入描述:
输入一行,表示用来倒排的句子
输出描述:
输出句子的倒排结果
方法一:正向统计,逆序输出
#include<iostream>
#include<vector>
#include<string>
using namespace std;
int main(){
string s;
while(getline(cin, s)){
vector<string> output;
output.clear();
string temp = "";
for(int i = 0; i < s.length(); i++){
if(s[i] >= 'a' && s[i] <= 'z' || s[i] >= 'A' && s[i] <= 'Z') //字母
temp += s[i]; //单词拼接
else{ //非字母,如果有单词才加入数组,没有说明前面是多个其他符号,忽略
if(temp.length() > 0){ //前面是记录了单词的
output.push_back(temp); //单词加入数组
temp = ""; //置空,重新添加字母
}
}
}
if(temp.length() > 0)
output.push_back(temp); //最后一个单词
for(int i = output.size() - 1; i >= 0; i--) //逆序输出
cout << output[i] << " ";
}
return 0;
}

方法二:正则表达式分割
import java.util.*;
public class Main {
public Main() {
}
public static void main(String[] args) {
Main solution = new Main();
Scanner in = new Scanner(System.in);
while (in.hasNextLine()) { //连续输入
String str = in.nextLine();
System.out.println(solution.reverse(str)); //经过倒排得到输出
}
}
public String reverse(String str) {
String[] words = str.split("[^A-Za-z]"); // 匹配非字母的字符进行分割
StringBuilder res = new StringBuilder();
for (int i = words.length - 1; i >= 0; i--) // 逆序添加分割完的单词并加入空格分隔
res.append(words[i]).append(" ");
return res.toString().trim();
}
}
方法三:模拟
import java.util.*;
public class Main {
public Main() {
}
public static void main(String[] args) {
Main solution = new Main();
Scanner in = new Scanner(System.in);
while (in.hasNextLine()) { //连续输入
String str = in.nextLine();
System.out.println(solution.reverse(str)); //经过倒排得到输出
}
}
public String reverse(String str) {
String[] words = str.split("[^A-Za-z]"); // 匹配非字母的字符进行分割
StringBuilder res = new StringBuilder();
for (int i = words.length - 1; i >= 0; i--) // 逆序添加分割完的单词并加入空格分隔
res.append(words[i]).append(" ");
return res.toString().trim();
}
}
HJ32 密码截取
描述
Catcher是MCA国的情报员,他工作时发现敌国会用一些对称的密码进行通信,比如像这些ABBA,ABA,A,123321,但是他们有时会在开始或结束时加入一些无关的字符以防止别国破解。比如进行下列变化 ABBA->12ABBA,ABA->ABAKK,123321->51233214 。因为截获的串太长了,而且存在多种可能的情况(abaaab可看作是aba,或baaab的加密形式),Cathcer的工作量实在是太大了,他只能向电脑高手求助,你能帮Catcher找出最长的有效密码串吗?
数据范围:字符串长度满足 1≤n≤2500
输入描述:
输入一个字符串(字符串的长度不超过2500)
输出描述:
返回有效密码串的最大长度
方法一:中心扩散法
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int main(){
string s;
while(cin >> s){
int maxlen = 0;
for(int i = 1; i < s.length(); i++){ //每个点都可以为中心
//计算以i-1和i为中心的偶数长度的回文子串长度
int low = i - 1, high = i;
while(low >= 0 && high < s.length() && s[low] == s[high]){ //中心两边必须都相同
low--;
high++;
}
maxlen = max(maxlen, high - low - 1);
//计算以i为中心的奇数长度的回文子串长度
low = i - 1, high = i + 1;
while(low >= 0 && high < s.length() && s[low] == s[high]){ //中心两边必须都相同
low--;
high++;
}
maxlen = max(maxlen, high - low - 1);
}
cout << maxlen << endl;
}
return 0;
}
方法二:动态规划


#include<iostream>
#include<string>
#include<algorithm>
#include<vector>
using namespace std;
int main(){
string s;
while(cin >> s){
int n = s.length();
vector<vector<bool> > dp(n, vector<bool>(n, false)); //dp[j][i]=1表示从j到i是回文子串
int maxlen = 1; //初始为1
for(int i = 0; i < n; i++){
for(int j = 0; j <= i; j++){
if(i == j) //奇数长度子串
dp[j][i] = true;
else if(i - j == 1) //偶数长度子串
dp[j][i] = (s[i] == s[j]);
else
dp[j][i] = (s[i] == s[j] && dp[j + 1][i - 1]); //这两个字符相等,同时中间缩也要相等
if(dp[j][i] && i - j + 1 > maxlen) //取最大
maxlen = i - j + 1;
}
}
cout << maxlen << endl;
}
return 0;
}
HJ33 整数与IP地址间的转换
描述
原理:ip地址的每段可以看成是一个0-255的整数,把每段拆分成一个二进制形式组合起来,然后把这个二进制数转变成
一个长整数。
举例:一个ip地址为10.0.3.193
每段数字 相对应的二进制数
10 00001010
0 00000000
3 00000011
193 11000001
组合起来即为:00001010 00000000 00000011 11000001,转换为10进制数就是:167773121,即该IP地址转换后的数字就是它了。
数据范围:保证输入的是合法的 IP 序列
输入描述:
输入
1 输入IP地址
2 输入10进制型的IP地址
输出描述:
输出
1 输出转换成10进制的IP地址
2 输出转换后的IP地址
方法一:逐位分割,逐位计算

#include<iostream>
#include<string>
using namespace std;
void toNum(string ip){
long num[4] = {0, 0, 0, 0};
int point = 0; //记录点出现的次数
for(int i = 0; i < ip.length(); i++){ //遍历ip字符串
if(ip[i] != '.'){ //通过.分割
num[point] = num[point] * 10 + ip[i] - '0';
}else{
point++; //点数增加
}
}
long output = num[0] << 24 | num[1] << 16 | num[2] << 8 | num[3]; //位运算组装
cout << output << endl;
}
void toIP(long num){
string output = "";
output += to_string((num >> 24) & 0xff); //取第一个八位二进制转换成字符
output += ".";
output += to_string((num >> 16) & 0xff); //取第二个八位二进制转换成字符
output += ".";
output += to_string((num >> 8) & 0xff); //取第三个八位二进制转换成字符
output += ".";
output += to_string(num & 0xff); //取第四个八位二进制转换成字符
cout << output << endl;
}
int main(){
string ip;
long num;
while(cin >> ip >> num){ //默认第一个是IP地址第二个是整数
toNum(ip);
toIP(num);
}
return 0;
}
方法二:正则表达式+字符串流输入输出
#include<iostream>
#include<sstream>
#include<regex>
#include<string>
using namespace std;
int main(){
string s;
while(cin >> s){
if(s.find_first_of('.') != string::npos){ //查找到有.的就是IP地址
long num[4];
stringstream(regex_replace(s, regex("\\."), " ")) >> num[0] >> num[1] >> num[2] >> num[3]; //用正则表达式分割后输入数组
long output = num[0] << 24 | num[1] << 16 | num[2] << 8 | num[3]; //位运算组装
cout << output << endl;
}else{ //否则是整数
long num;
stringstream(s) >> num; //流输入转数字
stringstream output;
output << ((num >> 24) & 0xff) << "." << ((num >> 16) & 0xff) << "." << ((num >> 8) & 0xff) << "." << (num & 0xff); //流输出格式
cout << output.str() << endl; //转字符串输出
}
}
return 0;
}
HJ34 图片整理
描述
Lily上课时使用字母数字图片教小朋友们学习英语单词,每次都需要把这些图片按照大小(ASCII码值从小到大)排列收好。请大家给Lily帮忙,通过代码解决。
Lily使用的图片使用字符"A"到"Z"、"a"到"z"、"0"到"9"表示。
数据范围:每组输入的字符串长度满足 1 \le n \le 1000 \1≤n≤1000
输入描述:
一行,一个字符串,字符串中的每个字符表示一张Lily使用的图片。
输出描述:
Lily的所有图片按照从小到大的顺序输出
方法一:sort函数快排
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int main(){
string s;
while(cin >> s){
sort(s.begin(), s.end()); //sort函数直接排序
cout << s << endl;
}
return 0;
}
方法二:桶排序思想

#include<iostream>
#include<string>
#include<vector>
using namespace std;
int main(){
string s;
while(cin >> s){
vector<int> table(123, 0); //统计123个ASCⅡ码出现次数
for(int i = 0; i < s.length(); i++){ //遍历字符串
table[s[i]]++; //相应ASCⅡ出现次数加1
}
for(int i = 0; i < table.size(); i++){ //遍历桶
while(table[i] > 0){ //依次输出所有桶中大于1的所有字符
cout << char(i);
table[i]--; //如果有多个要输出多次
}
}
cout << endl;
}
return 0;
}
HJ35 蛇形矩阵
描述
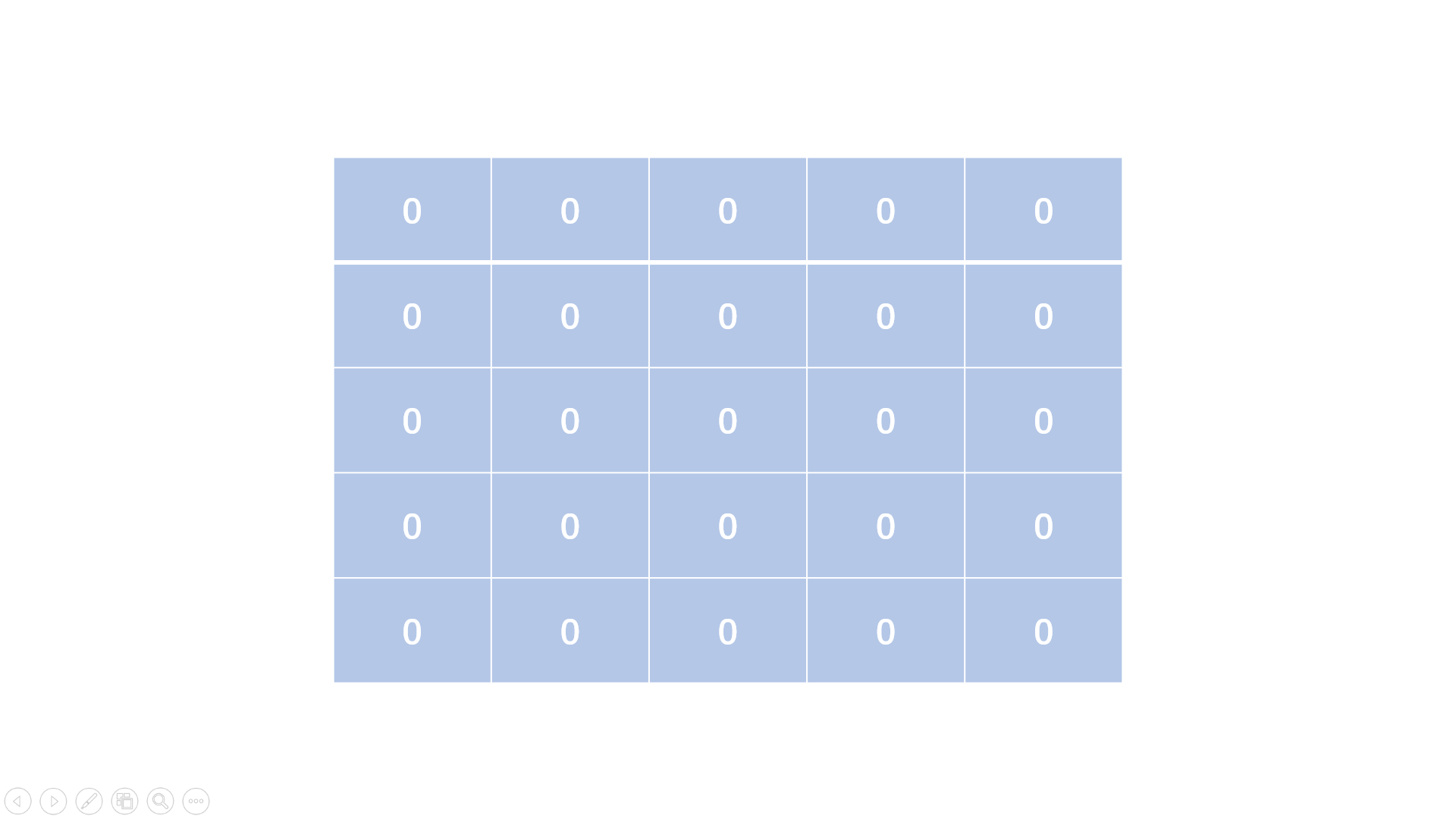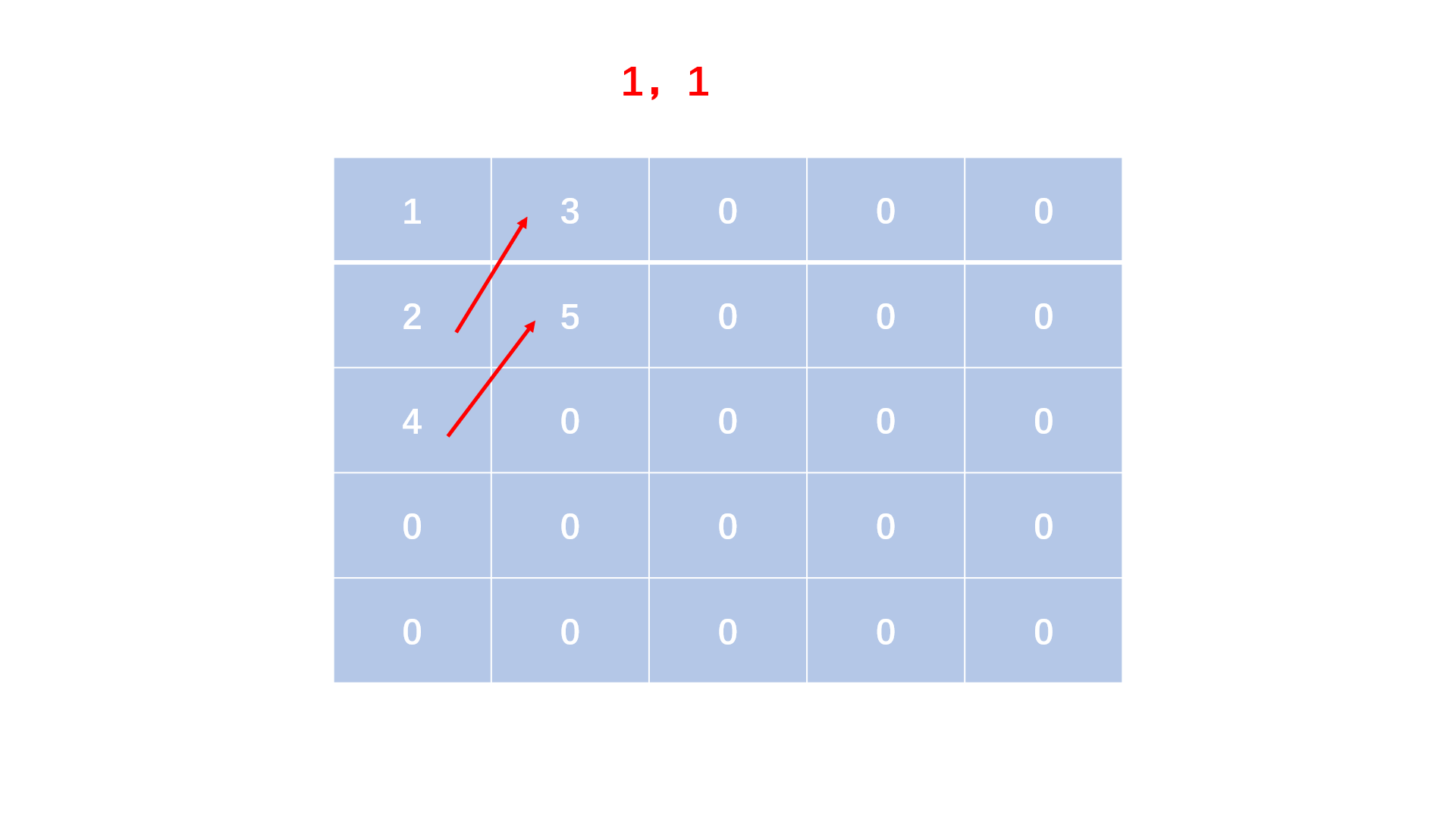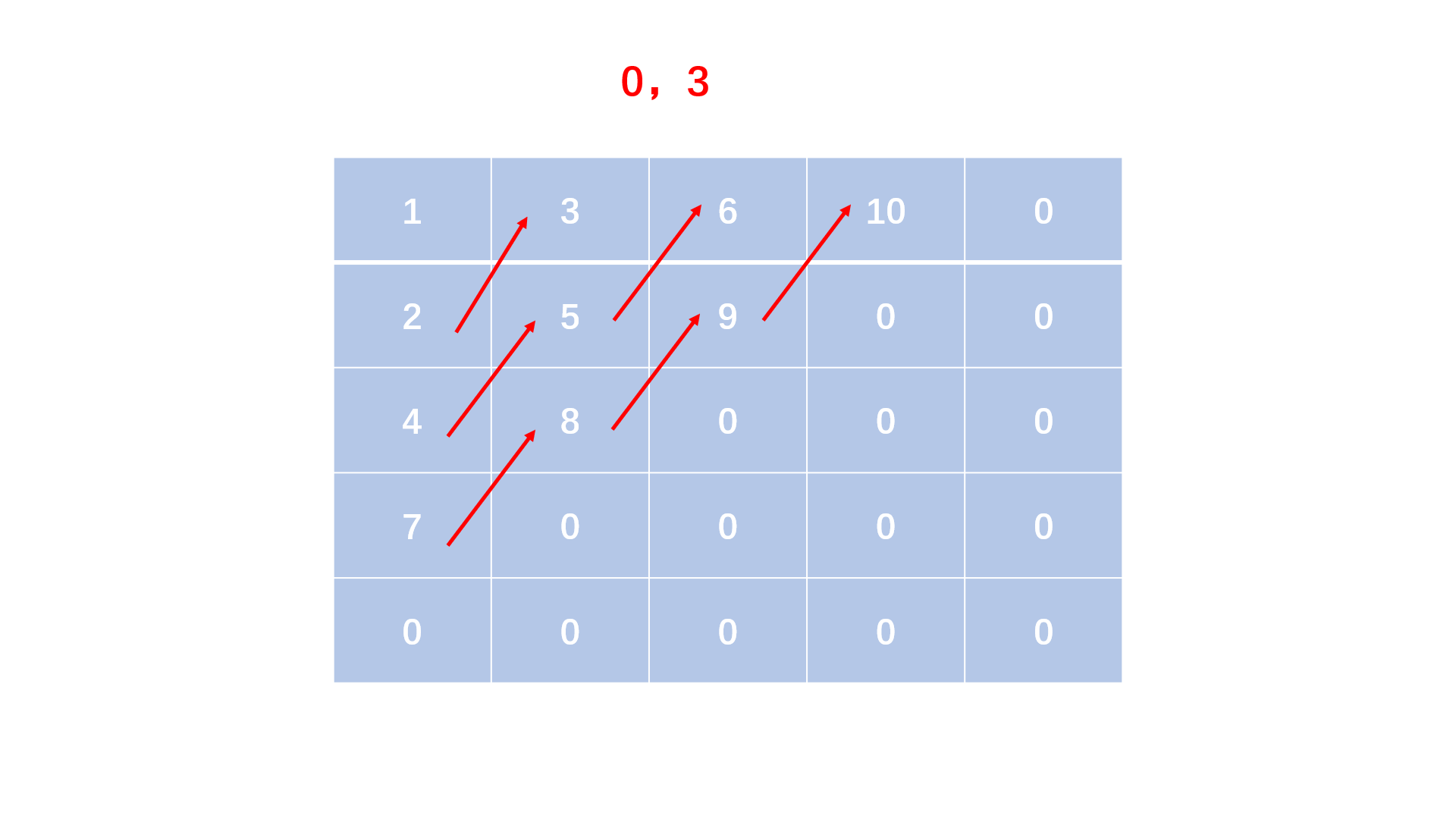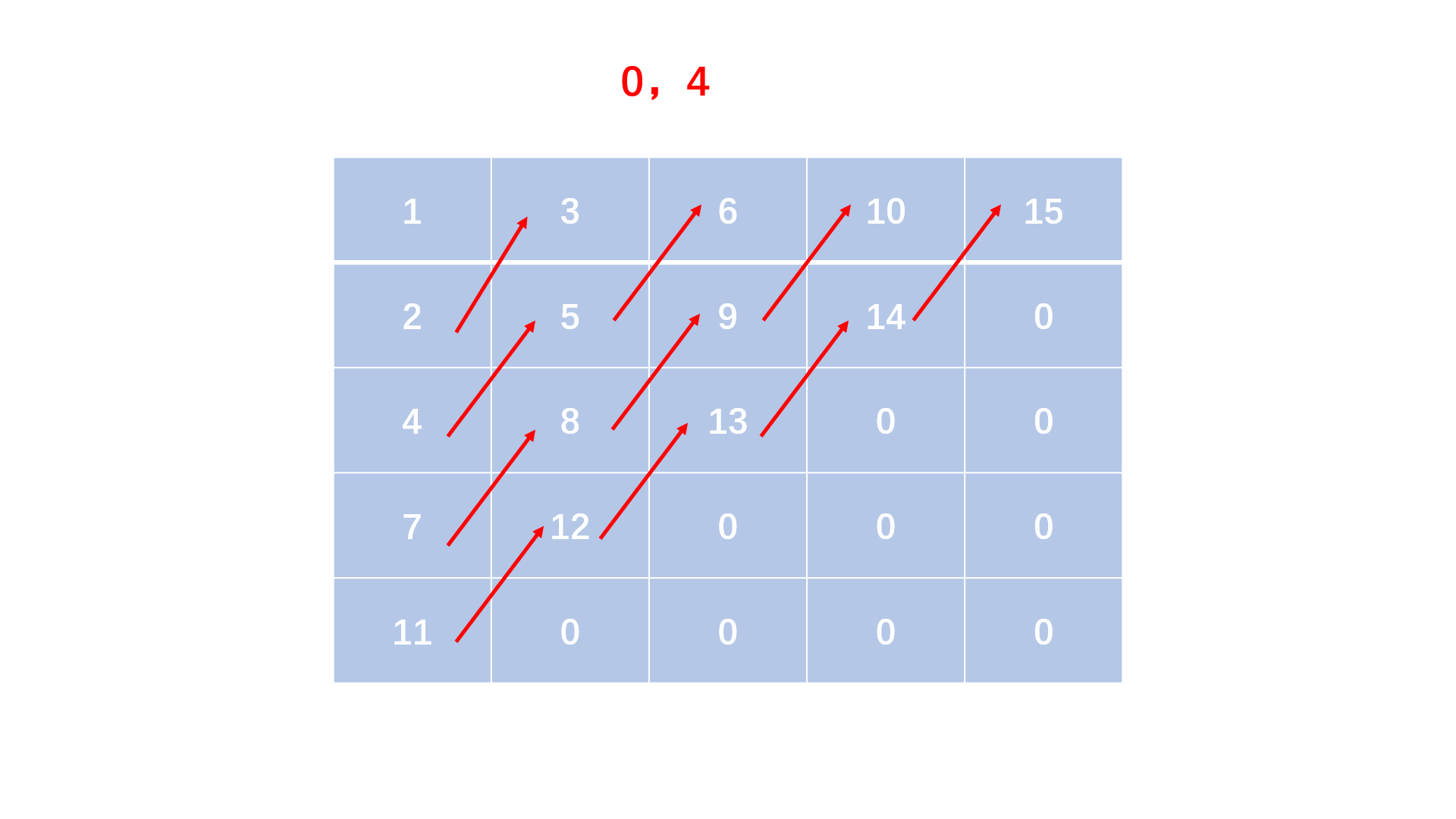
蛇形矩阵是由1开始的自然数依次排列成的一个矩阵上三角形。
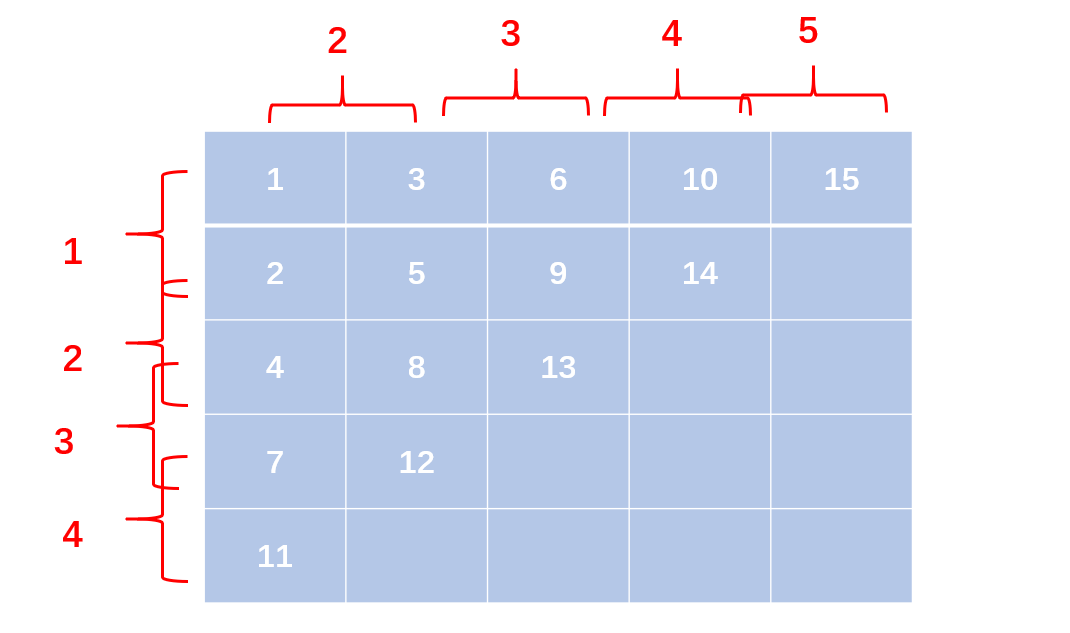
例如,当输入5时,应该输出的三角形为:
1 3 6 10 15
2 5 9 14
4 8 13
7 12
11
输入描述:
输入正整数N(N不大于100)
输出描述:
输出一个N行的蛇形矩阵。
方法一:顺序填表
#include<iostream>
#include<vector>
using namespace std;
int main(){
int n;
while(cin >> n){
vector<vector<int> > matrix(n, vector<int>(n, 0)); //定义一个n*n的矩阵
int num = 1;
for(int i = 0; i < n; i++){
int j = i, k = 0;
while(j >= 0){
matrix[j][k] = num; //录入数字
num++;
j--; //往右上方移
k++;
}
}
for(int i = 0; i < n; i++){ //遍历数组每一行
int j = 0;
while(matrix[i][j] != 0 && j < n){ //每行只输出前面非零部分
cout << matrix[i][j] << " ";
j++;
}
cout << endl; //换行
}
}
return 0;
}
方法二:数学规律
#include<iostream>
#include<vector>
using namespace std;
int main(){
int n;
while(cin >> n){
int k = 1; //起始元素为1
for(int i = 1; i <= n; i++){ //遍历每一行
cout << k << " "; //输出每行首
int temp = k;
for(int j = i + 1; j <= n; j++){ //遍历本行的数
temp += j; //每个数相差为j
cout << temp << " ";
}
cout << endl;
k += i; //下一行的首为这行首加上这行行号
}
}
return 0;
}
方法三:

#include <bits/stdc++.h>
using namespace std;
int a[105][105];
int main(){
int n;
while(cin >> n){
int num=1;
for(int i=0;i<n;i++){//下标总和
for(int j=0;j<=i;j++){//列下标
a[i-j][j]=num++;//行下标=下标总和-列下标
}
}
for(int i=0;i<n;i++){//遍历输出
for(int j=0;j<n-i;j++){
cout << a[i][j] << " ";
}
cout << endl;
}
}
return 0;
}
HJ36 字符串加密
描述
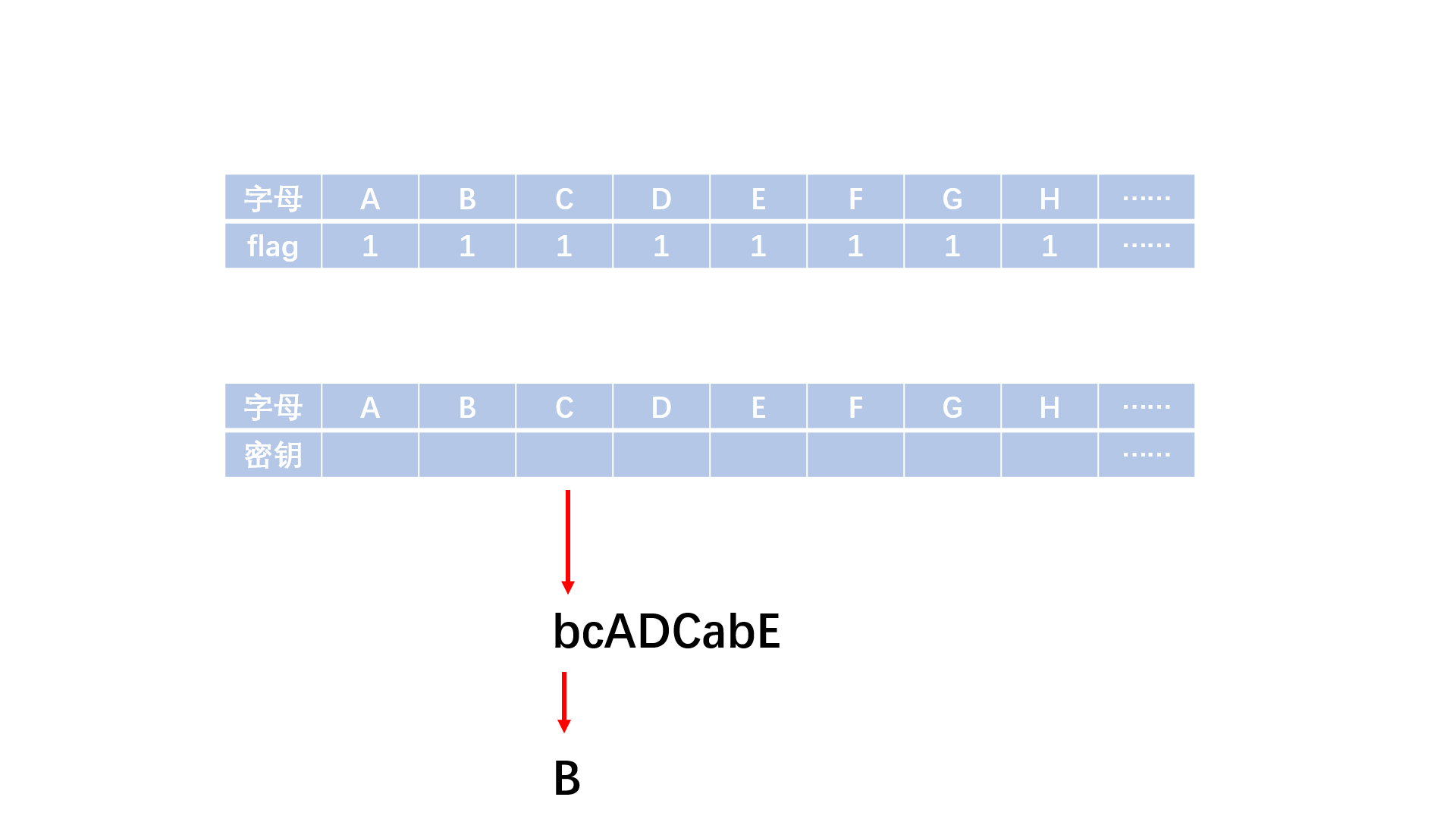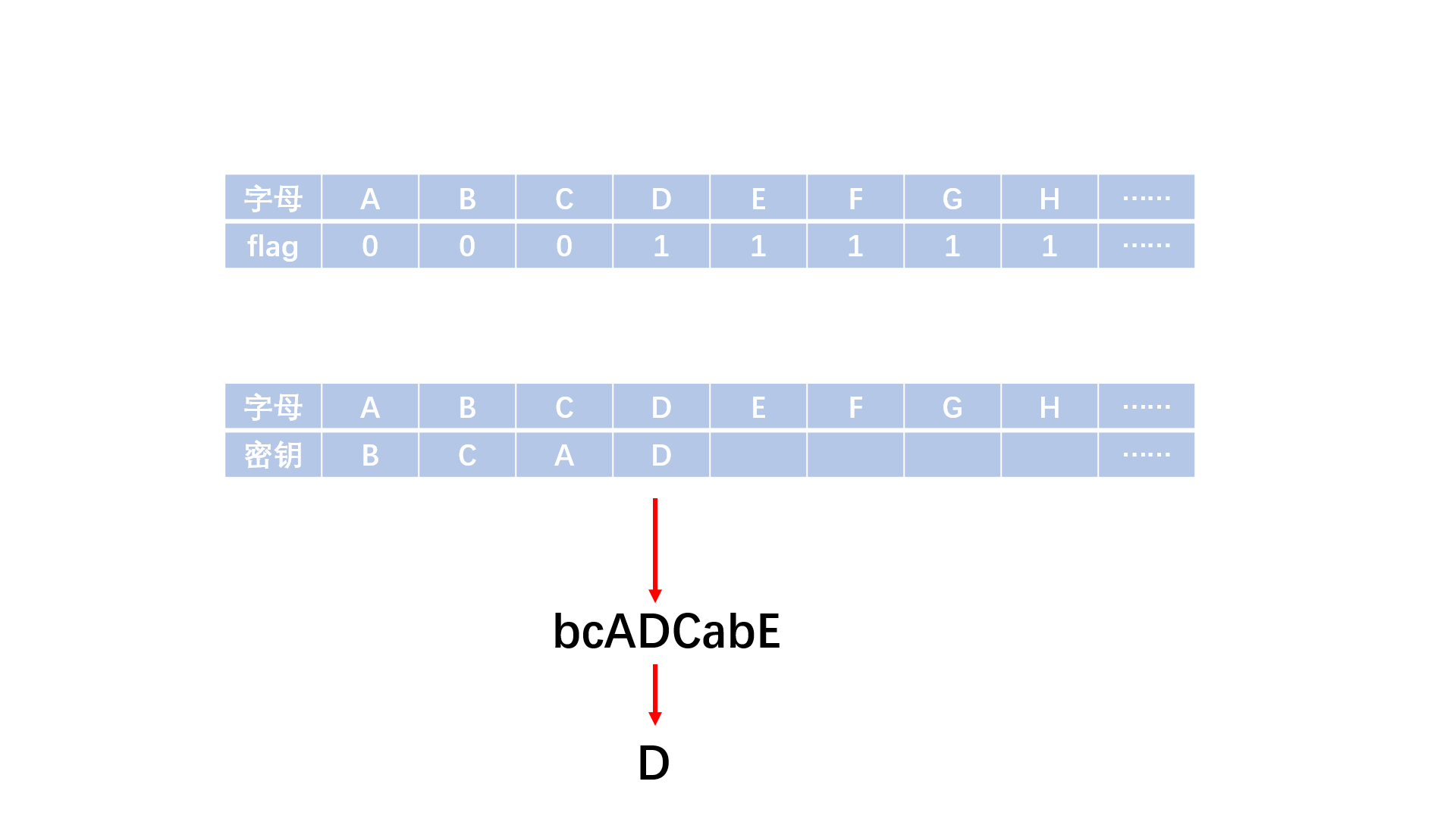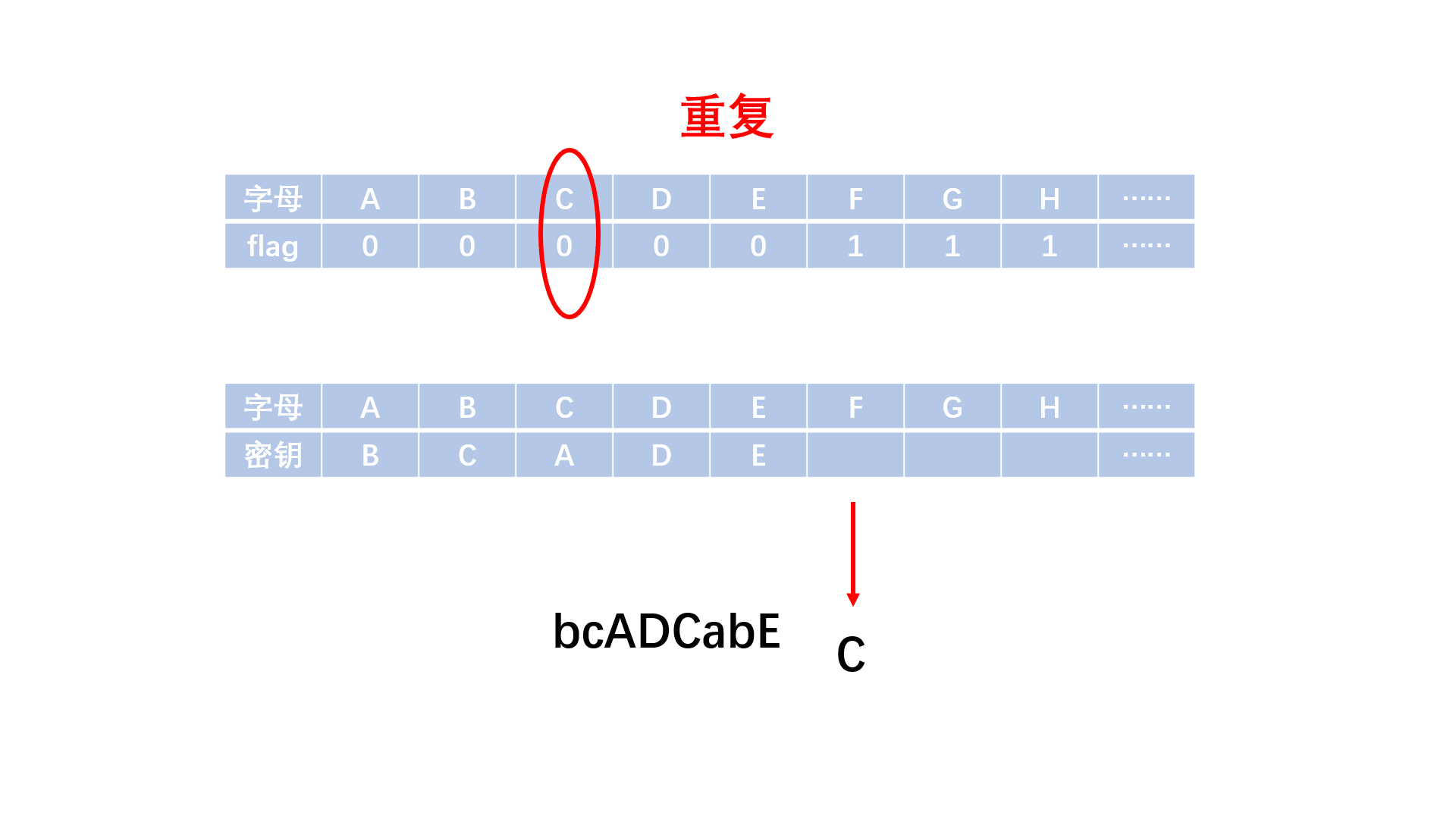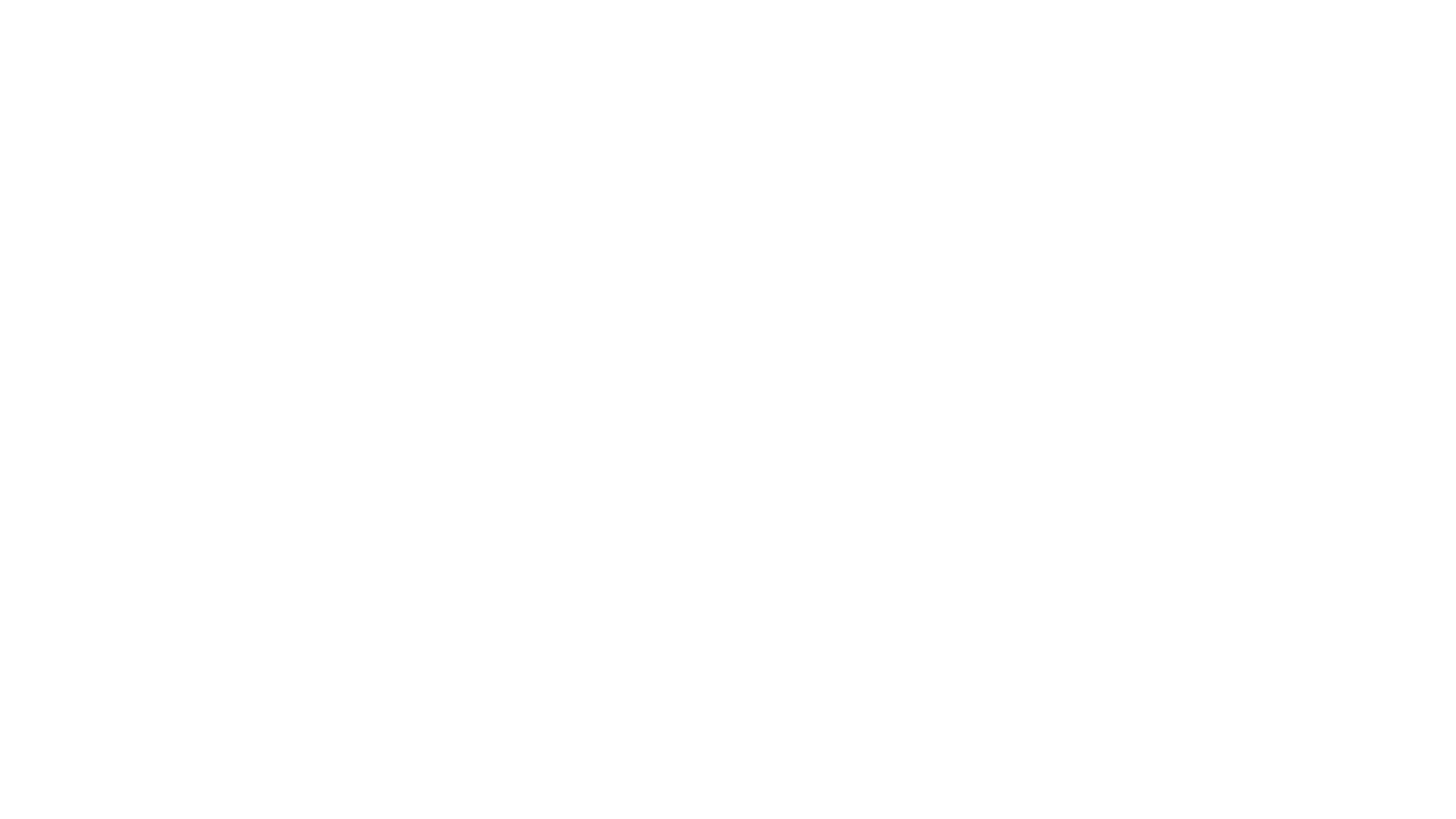
有一种技巧可以对数据进行加密,它使用一个单词作为它的密匙。下面是它的工作原理:首先,选择一个单词作为密匙,如TRAILBLAZERS。如果单词中包含有重复的字母,只保留第1个,将所得结果作为新字母表开头,并将新建立的字母表中未出现的字母按照正常字母表顺序加入新字母表。如下所示:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
T R A I L B Z E S C D F G H J K M N O P Q U V W X Y (实际需建立小写字母的字母表,此字母表仅为方便演示)
上面其他用字母表中剩余的字母填充完整。在对信息进行加密时,信息中的每个字母被固定于顶上那行,并用下面那行的对应字母一一取代原文的字母(字母字符的大小写状态应该保留)。因此,使用这个密匙, Attack AT DAWN (黎明时攻击)就会被加密为Tpptad TP ITVH。
请实现下述接口,通过指定的密匙和明文得到密文。
数据范围:1≤n≤100 ,保证输入的字符串中仅包含小写字母
输入描述:
先输入key和要加密的字符串
输出描述:
返回加密后的字符串
方法一:暴力解法
#include<iostream>
#include<string>
#include<cctype>
#include<vector>
#include<algorithm>
using namespace std;
int main(){
string key, words;
while(cin >> key >> words){
vector<char> v;
for(int i = 0; i < key.length(); i++){ //遍历字符串key
key[i] = toupper(key[i]); //全部转大写
auto it = find(v.begin(), v.end(), key[i]); //查找是否加入过了
if(it == v.end()) //非重复加入
v.push_back(key[i]);
}
for(char c = 'A'; c <= 'Z'; c++){ //从A遍历到Z
auto it = find(v.begin(), v.end(), c); //没有出现过
if(it == v.end())
v.push_back(c); //才加入
}
string output = "";
for(int i = 0; i < words.length(); i++){ //遍历要加密的字符串
if(islower(words[i])) //遇到小写字符
output += v[words[i] - 'a'] + 32; //需要在转出来的大写字母基础上加32
else
output += v[words[i] - 'A']; //大写字母直接替换
}
cout << output << endl;
}
return 0;
}
方法二:哈希方式优化
#include<iostream>
#include<string>
#include<cctype>
#include<vector>
#include<algorithm>
using namespace std;
int main(){
string key, words;
while(cin >> key >> words){
vector<char> v;
vector<bool> flag(26, true);
for(int i = 0; i < key.length(); i++){ //遍历字符串key
key[i] = toupper(key[i]); //全部转大写
if(flag[key[i] - 'A']){ //没有在密钥中出现过
flag[key[i] - 'A'] = false; //设置为该字母出现过了
v.push_back(key[i]); //加入密钥
}
}
for(char c = 'A'; c <= 'Z'; c++){ //从A遍历到Z
if(flag[c - 'A']){ //没有在密钥中出现过
flag[c - 'A'] = false; //设置为该字母出现过了
v.push_back(c); //加入密钥
}
}
string output = "";
for(int i = 0; i < words.length(); i++){ //遍历要加密的字符串
if(islower(words[i])) //遇到小写字符
output += v[words[i] - 'a'] + 32; //需要在转出来的大写字母基础上加32
else
output += v[words[i] - 'A']; //大写字母直接替换
}
cout << output << endl;
}
return 0;
}
方法三:简洁写法
#include<iostream>
#include<string>
#include<cctype>
#include<vector>
#include<algorithm>
using namespace std;
int main(){
string key, words;
while(cin >> key >> words){
vector<char> v;
vector<bool> flag(26, true);
for(int i = 0; i < key.length(); i++){ //遍历字符串key
key[i] = toupper(key[i]); //全部转大写
if(flag[key[i] - 'A']){ //没有在密钥中出现过
flag[key[i] - 'A'] = false; //设置为该字母出现过了
v.push_back(key[i]); //加入密钥
}
}
for(char c = 'A'; c <= 'Z'; c++){ //从A遍历到Z
if(flag[c - 'A']){ //没有在密钥中出现过
flag[c - 'A'] = false; //设置为该字母出现过了
v.push_back(c); //加入密钥
}
}
string output = "";
for(int i = 0; i < words.length(); i++){ //遍历要加密的字符串
if(islower(words[i])) //遇到小写字符
output += v[words[i] - 'a'] + 32; //需要在转出来的大写字母基础上加32
else
output += v[words[i] - 'A']; //大写字母直接替换
}
cout << output << endl;
}
return 0;
}
HJ37 统计每个月兔子的总数
描述
有一种兔子,从出生后第3个月起每个月都生一只兔子,小兔子长到第三个月后每个月又生一只兔子。
例子:假设一只兔子第3个月出生,那么它第5个月开始会每个月生一只兔子。
假如兔子都不死,问第n个月的兔子总数为多少?
数据范围:输入满足 1≤n≤31
输入描述:
输入一个int型整数表示第n个月
输出描述:
输出对应的兔子总数
方法一:递归

#include<iostream>
using namespace std;
int getSum(int n) { //求每个月兔子数
if(n == 1 || n == 2) //n=1或2跳出递归
return 1;
return getSum(n - 1) + getSum(n - 2); //返回前两个月相加
}
int main(){
int n;
while(cin >> n){ //每次输入n
cout << getSum(n) << endl;
}
return 0;
}
方法二:动态规划
#include<iostream>
#include<vector>
using namespace std;
int main(){
int n;
while(cin >> n){ //每次输入n
vector<int> dp(n + 1);
dp[1] = 1; //初始第一个月
dp[2] = 1; //第二个月
for(int i = 3; i <= n; i++) //后面的每个月由前面的累加
dp[i] = dp[i - 1] + dp[i - 2];
cout << dp[n] << endl;
}
return 0;
}
方法三:迭代
#include<iostream>
using namespace std;
int main(){
int n;
while(cin >> n){ //每次输入n
if(n <= 2) //前两个月直接输出
cout << 1 << endl;
else{
int dpi_2 = 1; //初始化第1个月
int dpi_1 = 1; //初始化第2个月
int output = 0;
for(int i = 3; i <= n; i++){
output = dpi_1 + dpi_2; //公式相加
dpi_2 = dpi_1; //变量更新
dpi_1 = output;
}
cout << output << endl;
}
}
return 0;
}
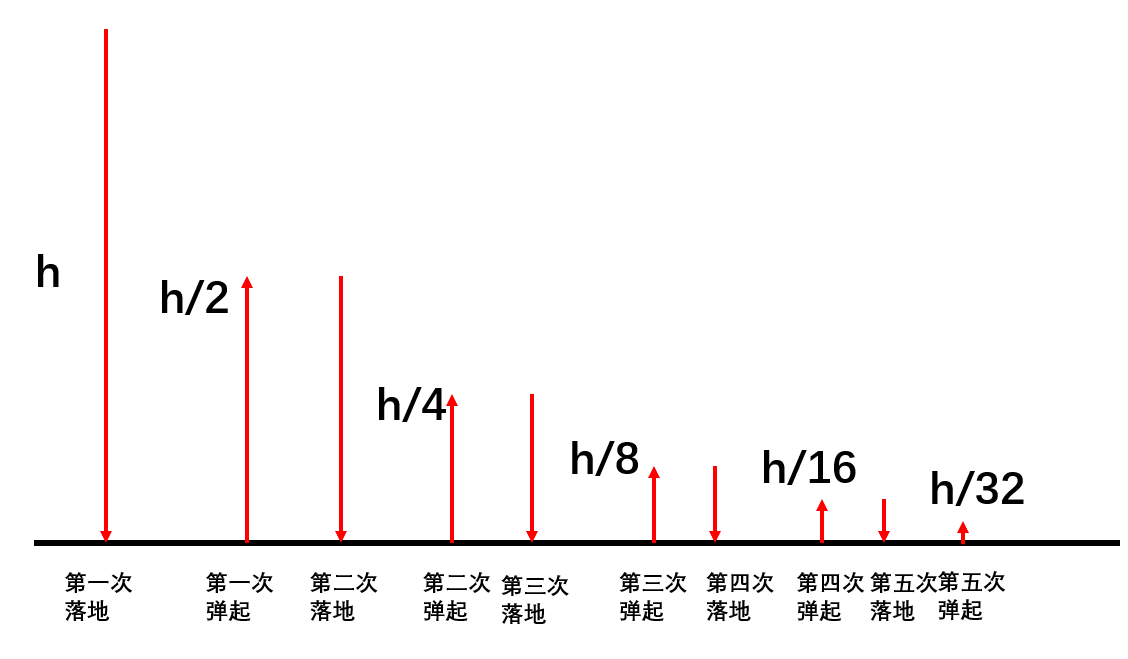
HJ38 求小球落地5次后所经历的路程和第5次反弹的高度
描述
假设一个球从任意高度自由落下,每次落地后反跳回原高度的一半; 再落下, 求它在第5次落地时,共经历多少米?第5次反弹多高?
数据范围:输入的小球初始高度满足 1≤n≤1000 ,且保证是一个整数
输入描述:
输入起始高度,int型
输出描述:
分别输出第5次落地时,共经过多少米以及第5次反弹多高。
注意:你可以认为你输出保留六位或以上小数的结果可以通过此题。
方法一:过程模拟

#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double h;
int n = 5;
cin >> h;
double dis = 0;
for(int i = 0; i < n; i++){
dis += h; //每次加上落下来的距离
h /= 2; //弹起距离缩短一半
if(i == n - 1)
cout << setprecision(6) << dis << endl << setprecision(6) << h << endl;
dis += h; //弹上去走的距离
}
return 0;
}
方法二:直接计算
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double h;
cin >> h;
cout << setprecision(6) << 2.875 * h << endl << setprecision(6) << 0.03125 * h << endl;
return 0;
}
HJ39 判断两个IP是否属于同一子网
描述
IP地址是由4个0-255之间的整数构成的,用"."符号相连。
二进制的IP地址格式有32位,例如:10000011,01101011,00000011,00011000;每八位用十进制表示就是131.107.3.24
子网掩码是用来判断任意两台计算机的IP地址是否属于同一子网络的根据。
子网掩码与IP地址结构相同,是32位二进制数,由1和0组成,且1和0分别连续,其中网络号部分全为“1”和主机号部分全为“0”。
你可以简单的认为子网掩码是一串连续的1和一串连续的0拼接而成的32位二进制数,左边部分都是1,右边部分都是0。
利用子网掩码可以判断两台主机是否中同一子网中。
若两台主机的IP地址分别与它们的子网掩码进行逻辑“与”运算(按位与/AND)后的结果相同,则说明这两台主机在同一子网中。
示例:
I P 地址 192.168.0.1
子网掩码 255.255.255.0
转化为二进制进行运算:
I P 地址 11000000.10101000.00000000.00000001
子网掩码 11111111.11111111.11111111.00000000
AND运算 11000000.10101000.00000000.00000000
转化为十进制后为:
192.168.0.0
I P 地址 192.168.0.254
子网掩码 255.255.255.0
转化为二进制进行运算:
I P 地址 11000000.10101000.00000000.11111110
子网掩码 11111111.11111111.11111111.00000000
AND运算 11000000.10101000.00000000.00000000
转化为十进制后为:
192.168.0.0
通过以上对两台计算机IP地址与子网掩码的AND运算后,我们可以看到它运算结果是一样的。均为192.168.0.0,所以这二台计算机可视为是同一子网络。
输入一个子网掩码以及两个ip地址,判断这两个ip地址是否是一个子网络。
若IP地址或子网掩码格式非法则输出1,若IP1与IP2属于同一子网络输出0,若IP1与IP2不属于同一子网络输出2。
注:
有效掩码与IP的性质为:
- 掩码与IP每一段在 0 - 255 之间
- 掩码的二进制字符串前缀为网络号,都由‘1’组成;后缀为主机号,都由'0'组成
输入描述:
3行输入,第1行是输入子网掩码、第2,3行是输入两个ip地址
题目的示例中给出了三组数据,但是在实际提交时,你的程序可以只处理一组数据(3行)。
输出描述:
若IP地址或子网掩码格式非法则输出1,若IP1与IP2属于同一子网络输出0,若IP1与IP2不属于同一子网络输出2
方法一:

#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> mask(4,0);
vector<int> ip1(4,0);
vector<int> ip2(4,0);
char c;
while (cin>>mask[0]>>c>>mask[1]>>c>>mask[2]>>c>>mask[3])//输入掩码
{
int flag = -1;//结果
cin>>ip1[0]>>c>>ip1[1]>>c>>ip1[2]>>c>>ip1[3];//第一个ip地址
cin>>ip2[0]>>c>>ip2[1]>>c>>ip2[2]>>c>>ip2[3];//第二个ip地址
for(int i=0;i<4;i++)//两个ip地址和掩码每一段都要在0-255之间
{
if(mask[i]<0 || mask[i]>255 || ip1[i]<0 || ip1[i]>255 ||ip2[i]<0 || ip2[i]>255)
{
flag = 1;//格式非法
break;
}
}
for(int i=0;i<3;i++)//掩码的网络号全为1,主机号全为0
{
if(mask[i]<255 && mask[i+1]>0)
{
flag = 1;
break;
}
}
if(flag==1)//格式非法,输出1
{
cout<<flag<<endl;
}else{
for(int i=0;i<4;i++)
{
if((mask[i]&ip1[i])!=(mask[i]&ip2[i]))//两个ip地址和掩码做AND操作
{
flag = 2;
break;
}else{//AND操作结果不相同
flag = 0;
}
}
cout<<flag<<endl;
}
}
return 0;
}
方法二:正则表达式
#include<iostream>
#include<vector>
#include<string>
#include<regex>
using namespace std;
int main()
{
vector<int> mask(4,0);
vector<int> ip1(4,0);
vector<int> ip2(4,0);
regex pattern("((25[0-5]|2[0-4]\\d|1\\d\\d|[1-9]\\d|\\d)\.){4}");//匹配0.0.0.0.-255.255.255.255.的正则表达式
char c;
while (cin>>mask[0]>>c>>mask[1]>>c>>mask[2]>>c>>mask[3])//输入掩码
{
int flag = -1;//结果
cin>>ip1[0]>>c>>ip1[1]>>c>>ip1[2]>>c>>ip1[3];//第一个ip地址
cin>>ip2[0]>>c>>ip2[1]>>c>>ip2[2]>>c>>ip2[3];//第二个ip地址
string str_mask,str_ip1,str_ip2;
for(int i=0;i<4;i++){
str_mask+=to_string(mask[i])+'.';
str_ip1+=to_string(ip1[i])+'.';
str_ip2+=to_string(ip2[i])+'.';
}
if((regex_match(str_mask,pattern)&®ex_match(str_ip1,pattern)&®ex_match(str_ip2,pattern))==false)
{
flag=1;
}
for(int i=0;i<3;i++)//掩码的网络号全为1,主机号全为0
{
if(mask[i]<255 && mask[i+1]>0)
{
flag = 1;
break;
}
}
if(flag==1)//格式非法,输出1
{
cout<<flag<<endl;
}else{
for(int i=0;i<4;i++)
{
if((mask[i]&ip1[i])!=(mask[i]&ip2[i]))//两个ip地址和掩码做AND操作
{
flag = 2;
break;
}else{//AND操作结果相同
flag = 0;
}
}
cout<<flag<<endl;
}
}
return 0;
}
HJ40 统计字符
描述
输入一行字符,分别统计出包含英文字母、空格、数字和其它字符的个数。
数据范围:输入的字符串长度满足 ≤n≤1000
输入描述:
输入一行字符串,可以有空格
输出描述:
统计其中英文字符,空格字符,数字字符,其他字符的个数
方法一:ASCII码统计

#include<iostream>
#include<string>
using namespace std;
int main(){
string str;
int num_e,num_w,num_n,num_o;//英文字母、空格、数字、其他字符的数量
num_e=num_w=num_n=num_o=0;
while(getline(cin,str))//逐行统计
{
num_e=num_w=num_n=num_o=0;//每从新的一行开始统计的时候都要清零
for(int i=0;i<str.size();i++){
if(str[i]>='0'&&str[i]<='9'){//数字
num_n++;
}else if((str[i]>='a'&&str[i]<='z')||(str[i]>='A'&&str[i]<='Z')){//英文字母
num_e++;
}else if(str[i]==' '){//空格
num_w++;
}else num_o++;//其他字符
}
cout<<num_e<<endl<<num_w<<endl<<num_n<<endl<<num_o<<endl;
}
return 0;
}
方法二:isspace()
除了比较ASCⅡ码,我们还可以调用字符串string类中的内置函数,一些内置函数如下:
字符判断函数
作用
isalpha()
判断字符是否是字母('a'-'z' 'A'-'Z')
isdigit()
判断字符是否是数字
isspace()
判断字符是否是空格、制表符、换行等标准空白
isalnum()
判断字符是否是字母或者数字
ispunct()
判断字符是标点符号
islower()
判断字符是否是小写字母('a'-'z')
isupper()
判断字符是否是大写字母('A'-'Z')
#include<iostream>
#include<string>
using namespace std;
int main(){
string str;
int num_e,num_w,num_n,num_o;//英文字母、空格、数字、其他字符的数量
num_e=num_w=num_n=num_o=0;
while(getline(cin,str))//逐行统计
{
num_e=num_w=num_n=num_o=0;//每从新的一行开始统计的时候都要清零
for(int i=0;i<str.size();i++){
if(isdigit(str[i])){//数字
num_n++;
}else if(isalpha(str[i])){//英文字母
num_e++;
}else if(isspace(str[i])){//空格
num_w++;
}else num_o++;//其他字符
}
cout<<num_e<<endl<<num_w<<endl<<num_n<<endl<<num_o<<endl;
}
return 0;
}
HJ41 称砝码
描述
现有n种砝码,重量互不相等,分别为 m1,m2,m3…mn ;
每种砝码对应的数量为 x1,x2,x3...xn 。现在要用这些砝码去称物体的重量(放在同一侧),问能称出多少种不同的重量。
注:
称重重量包括 0
数据范围:每组输入数据满足 1≤n≤10 , 1≤mi≤2000 , 1≤xi≤10
输入描述:
对于每组测试数据:
第一行:n --- 砝码的种数(范围[1,10])
第二行:m1 m2 m3 ... mn --- 每种砝码的重量(范围[1,2000])
第三行:x1 x2 x3 .... xn --- 每种砝码对应的数量(范围[1,10])
输出描述:
利用给定的砝码可以称出的不同的重量数
方法一:集合

#include<iostream>
#include<vector>
#include<unordered_set>
#include<algorithm>
using namespace std;
int main(){
int n;
while(cin >> n){
vector<int> weight(n);
vector<int> num(n);
for(int i = 0; i < n; i++) //输入n种砝码重量
cin >> weight[i];
for(int i = 0; i < n; i++) //输入n种砝码的数量
cin >> num[i];
unordered_set<int> s; //集合用于去重
s.insert(0); //0也是一种
for(int i = 0; i < n; i++){ //对于每一种砝码
for(int j = 1; j <= num[i]; j++){ //用完之前数量之前
unordered_set<int> temp(s);
for(auto iter = temp.begin(); iter != temp.end(); iter++) //当前集合每个都可以加一次
s.insert(*iter + weight[i]);
}
}
cout << s.size() << endl; //最后集合的大小就是种类
}
return 0;
}
方法二:动态规划
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main(){
int n;
while(cin >> n){
vector<int> weight(n);
vector<int> num(n);
int sum = 0;
for(int i = 0; i < n; i++) //输入n种砝码重量
cin >> weight[i];
for(int i = 0; i < n; i++){//输入n种砝码的数量
cin >> num[i];
sum += num[i] * weight[i]; //砝码总重量
}
vector<bool> dp(sum + 1, false); //记录0到sum是否可行
dp[0] = true;
for(int i = 0; i < n; i++){ //遍历每一种砝码
for(int j = 0; j < num[i]; j++){ //遍历砝码每一个数量
for(int k = sum; k >= weight[i]; k--) //每次剩余的每个都可以添加
if(dp[k - weight[i]])
dp[k] = 1;
}
}
int count = 0;
for(int i = 0; i <= sum; i++) //找到为1的就是可以组成的质量,计数
if(dp[i])
count++;
cout << count << endl;
}
return 0;
}
HJ42 学英语
描述
Jessi初学英语,为了快速读出一串数字,编写程序将数字转换成英文:
具体规则如下:
1.在英语读法中三位数字看成一整体,后面再加一个计数单位。从最右边往左数,三位一单位,例如12,345 等
2.每三位数后记得带上计数单位 分别是thousand, million, billion.
3.公式:百万以下千以上的数 X thousand X, 10亿以下百万以上的数:X million X thousand X, 10 亿以上的数:X billion X million X thousand X. 每个X分别代表三位数或两位数或一位数。
4.在英式英语中百位数和十位数之间要加and,美式英语中则会省略,我们这个题目采用加上and,百分位为零的话,这道题目我们省略and
下面再看几个数字例句:
22: twenty two
100: one hundred
145: one hundred and forty five
1,234: one thousand two hundred and thirty four
8,088: eight thousand (and) eighty eight (注:这个and可加可不加,这个题目我们选择不加)
486,669: four hundred and eighty six thousand six hundred and sixty nine
1,652,510: one million six hundred and fifty two thousand five hundred and ten
说明:
数字为正整数,不考虑小数,转化结果为英文小写;
保证输入的数据合法
关键字提示:and,billion,million,thousand,hundred。
数据范围:1≤n≤2000000
输入描述:
输入一个long型整数
输出描述:
输出相应的英文写法
方法一:

#include <iostream>
#include <string>
using namespace std;
const string ones[] = { "zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine" };
const string tens[] = { "ten","eleven","twelve","thirteen","fourteen","fifteen","sixteen","seventeen","eighteen","nineteen" };
const string twenties[] = { "zero","ten","twenty","thirty","forty","fifty","sixty","seventy","eighty","ninety" };
const int ihundreds[] = { (int)1e2, (int)1e3, (int)1e6, (int)1e9, (int)1e12 };
const string hundreds[] = { "hundred", "thousand", "million", "billion" };
string itoe(long long n){
if (0<=n && n<=9){//个位数,直接输出
return ones[n];
}
if (10<=n && n<20){//十位数,直接输出
return tens[n%10];
}
if (20<=n && n<1e2){//20-100
return twenties[n/10] + (n%10 ? " " + ones[n%10] : "");
}
for (int i=0; i < 4; i++){//大于100
if (n < ihundreds[i+1]) {//确定范围
return itoe(n/ihundreds[i]) + " " + hundreds[i] + (n%ihundreds[i] ? (i ? " ": " and ") + itoe(n%ihundreds[i]) : "");//递归转换
}
}
return "";
}
int main(){
long long n;
while (cin>>n){
cout<<itoe(n)<<endl;
}
return 0;
}
方法二:模拟
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
const vector<string> num1 = {"", "thousand", "million", "billion"};
const vector<string> num2 = {"", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
const vector<string> num3 = {"", "", "twenty", "thirty", "forty", "fifty", "sixty", "seventy", "eighty", "ninety"};
const vector<string> num4 = {"ten", "eleven", "twelve", "thirteen", "fourteen", "fifteen", "sixteen", "seventeen", "eighteen", "nineteen"};
int main(){
long n;
while(cin >> n){
vector<string> res;
string s = to_string(n);
vector<string> v;
int i = s.size() - 1;//此时i指向数字的最低位
while(i >= 0){//从低位开始每三位划分
int j = i;
while(j > 0 && i - j < 2) j--;
v.push_back(s.substr(j, i - j + 1));
i = j - 1;
}
reverse(v.begin(), v.end());
for(int i = 0; i < v.size(); ++i){
if(v[i].size() == 3){//三位数字
if(v[i][0] - '0' != 0){//最高位不为0时,需要跟上百
res.push_back(num2[v[i][0] - '0']);
res.push_back("hundred");
if(v[i][1] - '0' != 0 || v[i][2] - '0' != 0){
res.push_back("and");//个位或十位不为零食,需要and
}
}
if(v[i][1] - '0' == 1){//处理10-19
res.push_back(num4[v[i][2] - '0']);
}else {//处理20-99
res.push_back(num3[v[i][1] - '0']);
res.push_back(num2[v[i][2] - '0']);
}
}else if(v[i].size() == 2){//两位数字
if(v[i][0] - '0' == 1){//10-19
res.push_back(num4[v[i][1] - '0']);
}
else {//20-99
res.push_back(num3[v[i][0] - '0']);
res.push_back(num2[v[i][1] - '0']);
}
}else{//只有一位数字,直接在num2中对应英文,0-9
res.push_back(num2[v[i][0] - '0']);
}
res.push_back(num1[v.size() - i - 1]);//确定每三位的单位
}
for(auto it : res){//输出最后结果
if(it != "")
cout << it << ' ';
}
cout << endl;
}
return 0;
}
HJ43 迷宫问题
描述
定义一个二维数组 N*M ,如 5 × 5 数组下所示:
int maze[5][5] = {
0, 1, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的路线。入口点为[0,0],既第一格是可以走的路。
数据范围: 2≤n,m≤10 , 输入的内容只包含 0≤val≤1
输入描述:
输入两个整数,分别表示二维数组的行数,列数。再输入相应的数组,其中的1表示墙壁,0表示可以走的路。数据保证有唯一解,不考虑有多解的情况,即迷宫只有一条通道。
输出描述:
左上角到右下角的最短路径,格式如样例所示。
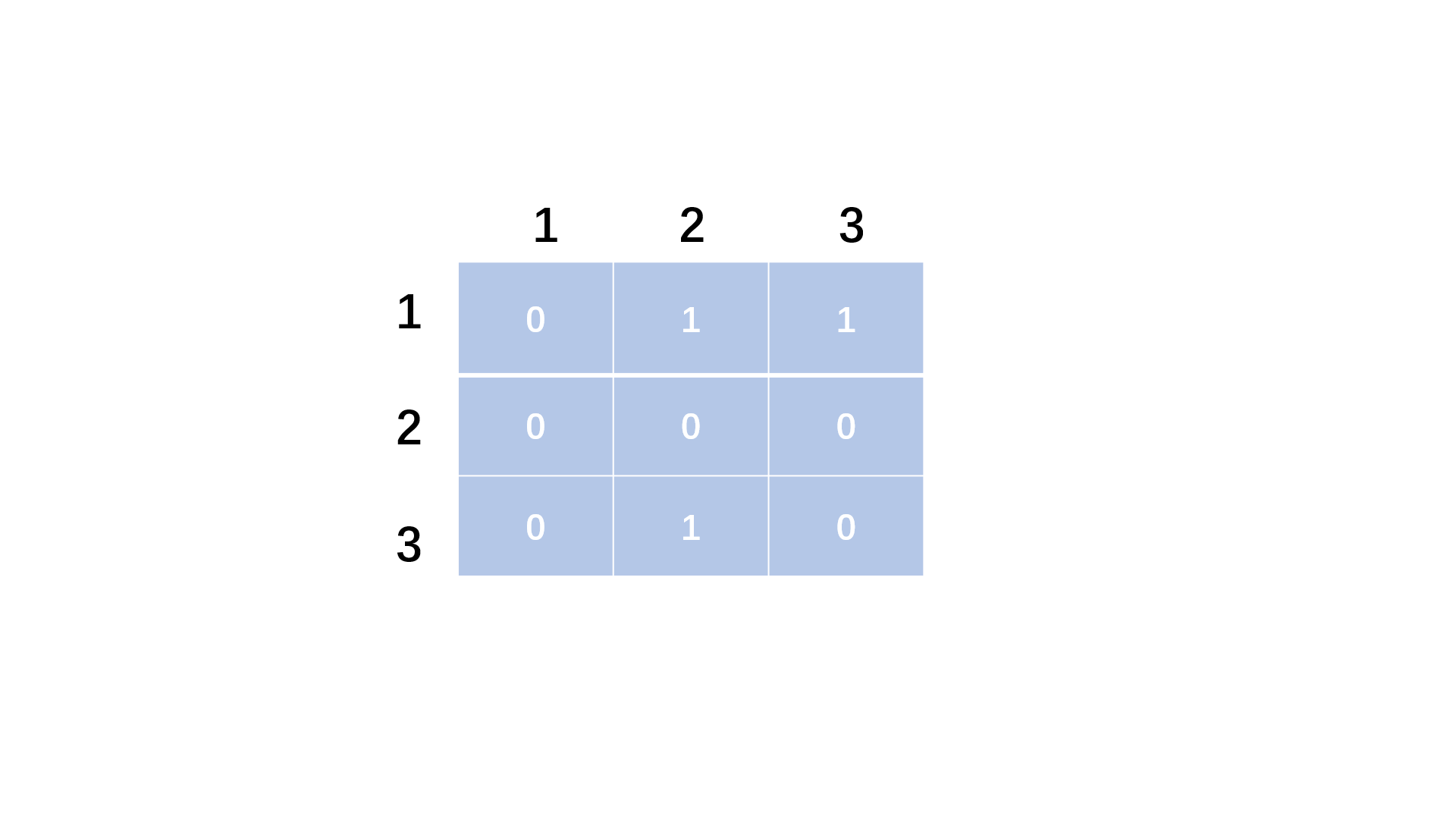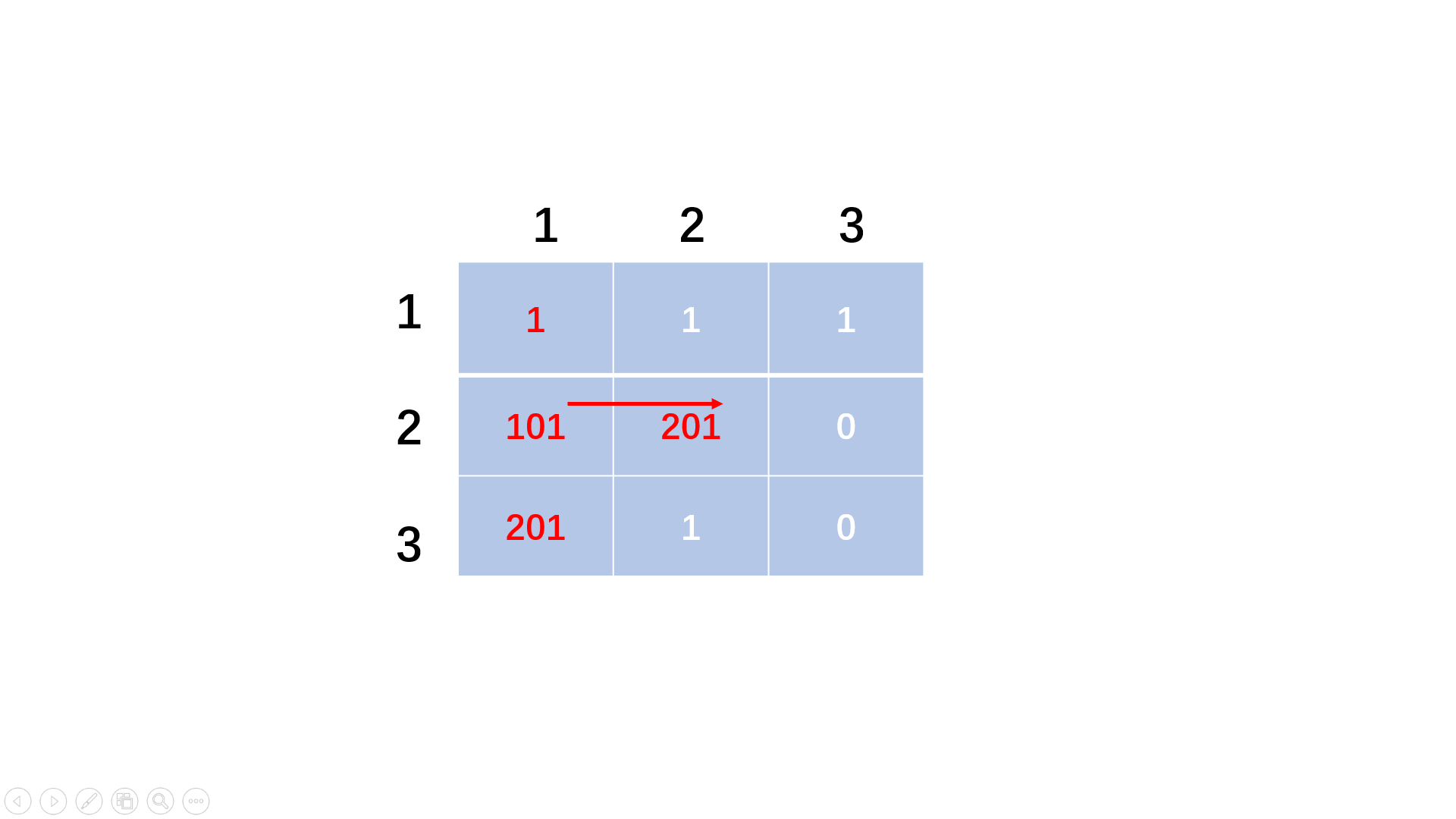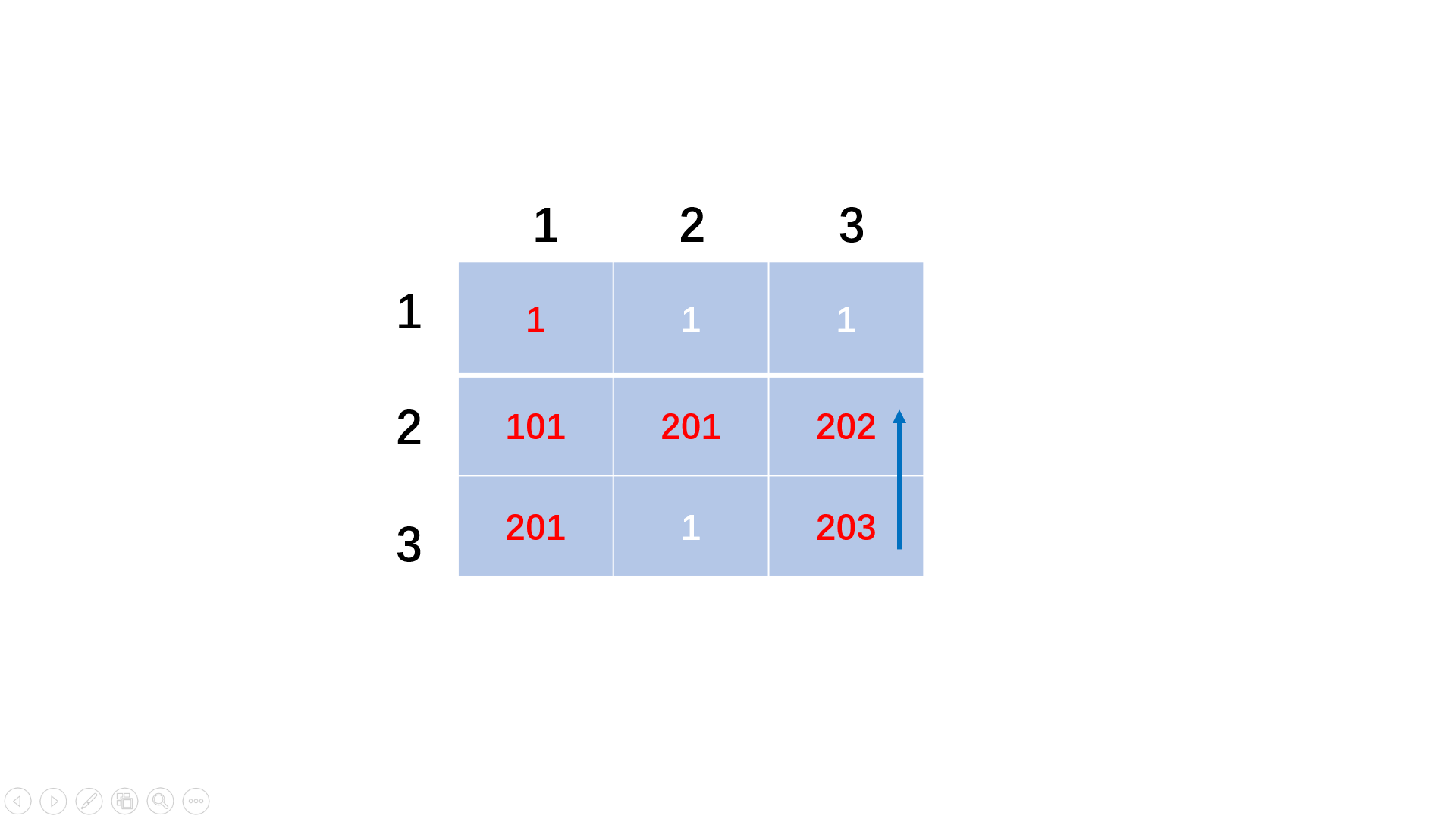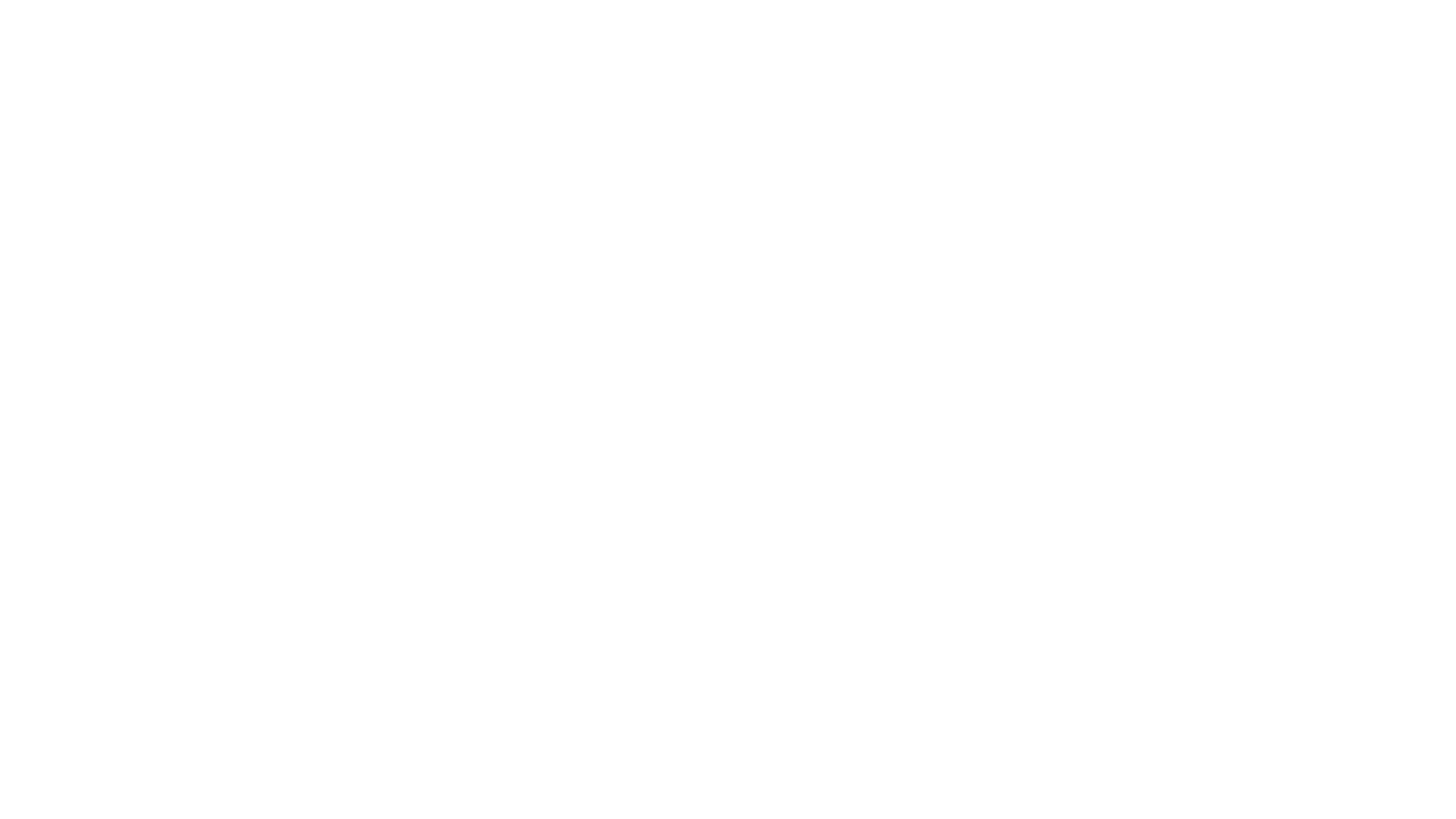
方法一:dfs递归+回溯
#include<iostream>
#include<vector>
using namespace std;
vector<pair<int, int> > res;
void dfs(vector<vector<int>>& matrix, int n, int m, int i, int j, vector<pair<int, int>>& paths){
paths.push_back(make_pair(i, j)); //记入路径
matrix[i][j] = 1; //经过部分设置为1,表示后续不能经过
if(i == n - 1 && j == m - 1){ //到达终点
res = paths;
return;
}
//四个方向搜索
if(i + 1 < n && matrix[i + 1][j] == 0)
dfs(matrix, n, m, i + 1, j, paths);
if(j + 1 < m && matrix[i][j + 1] == 0)
dfs(matrix, n, m, i, j + 1, paths);
if(i - 1 >= 0 && matrix[i - 1][j] == 0)
dfs(matrix, n, m, i - 1, j, paths);
if(j - 1 >= 0 && matrix[i][j - 1] == 0)
dfs(matrix, n, m, i, j - 1, paths);
paths.pop_back(); //回溯
matrix[i][j] = 0;
}
int main(){
int n, m;
while(cin >> n >> m){
vector<vector<int> > matrix(n, vector<int>(m, 0));
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++) //输入迷宫矩阵
cin >> matrix[i][j];
vector<pair<int, int> > paths; //记录临时路径
dfs(matrix, n, m, 0, 0, paths); //dfs遍历矩阵
for(int i = 0; i < res.size(); i++) //输出路径
cout << "(" << res[i].first << "," << res[i].second << ")" << endl;
}
return 0;
}
方法二:dfs非递归+逆向搜索
#include<iostream>
#include<vector>
#include<stack>
using namespace std;
int main(){
int n, m;
int direct[4][2] = {{-1, 0}, {0, -1}, {1, 0}, {0, 1}};
while(cin >> n >> m){
vector<vector<int> > matrix(n + 1, vector<int>(m + 1, 0));
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++) //输入迷宫矩阵
cin >> matrix[i][j];
stack<pair<int, int> > s; //记录深度优先的栈
s.push(make_pair(1, 1)); //第一个结点入栈
matrix[1][1] = 1;
vector<pair<int, int> > res;
while(!s.empty()){
auto p = s.top();
s.pop();
for(int i = 0; i < 4; i++){ //四个方向
int x = p.first + direct[i][0];
int y = p.second + direct[i][1];
if(x > 0 && y > 0 && x <= n && y <= m && matrix[x][y] == 0){ //确保不越界再看是否为0
matrix[x][y] = p.first * 100 + p.second; //修改矩阵为前一个的坐标,百位为i,个位为j
if(x == n && y == m) //到达终点
break;
s.push(make_pair(x, y));
}
}
}
int i = n;
int j = m;
while(matrix[i][j] != 1){ //直到遇到起点
res.push_back(make_pair(i, j)); //从终点逆向添加
int temp = matrix[i][j];
i = temp / 100;
j = temp % 100;
}
res.push_back(make_pair(1, 1)); //添加起点
for(int i = res.size() - 1; i >= 0; i--) //反向输出路径
cout << "(" << res[i].first - 1<< "," << res[i].second - 1<< ")" << endl;
}
return 0;
}
方法三:BFS

#include <bits/stdc++.h>
using namespace std;
int a[15][15],vis[15][15];
int b[4][2]={{-1,0},{0,1},{1,0},{0,-1}};//上下左右四个方向
pair<int,int> fa[15][15];//记录当前下标的父亲下标
void dfs(int x,int y){//dfs打印路径
if(x==0&&y==0)//如果到达左上角,则退出
return;
auto t=fa[x][y];
dfs(t.first,t.second);
printf("(%d,%d)\n",x,y);
}
int main(){
int n,m;
while(cin >> n >> m){
for(int i=0;i<n;i++)
for(int j=0;j<m;j++)
cin >> a[i][j];//输入迷宫
memset(vis,0,sizeof(vis));
memset(fa,0,sizeof(fa));
queue<pair<int,int>> q;//队列
q.push({0,0});//左上角坐标入队列
vis[0][0]=1;
while(!q.empty()){
auto u=q.front();
q.pop();
if(u.first==n-1&&u.second==m-1){
break;
}
for(int i=0;i<4;i++){//遍历四个方向
int nx=u.first+b[i][0],ny=u.second+b[i][1];
if(nx<0||nx>=n||ny<0||ny>=m)
continue;
if(vis[nx][ny]==0&&a[nx][ny]==0){//如果当前坐标未访问过并且可以走,则入队列,并且当前坐标指定父亲坐标
fa[nx][ny]={u.first,u.second};
q.push({nx,ny});
vis[nx][ny]=1;
}
}
}
printf("(%d,%d)\n",0,0);
dfs(n-1,m-1);
}
return 0;
}
HJ44 Sudoku
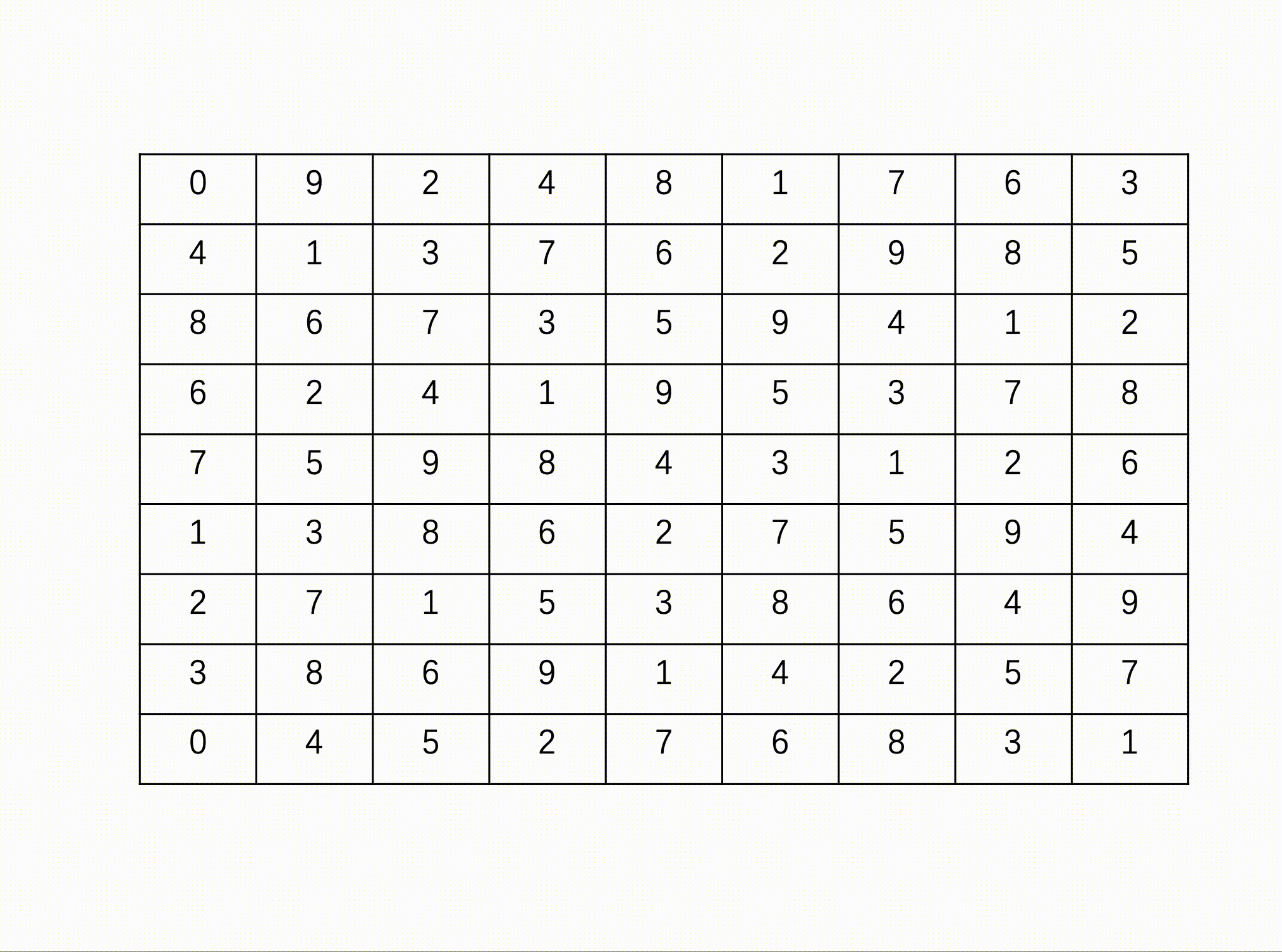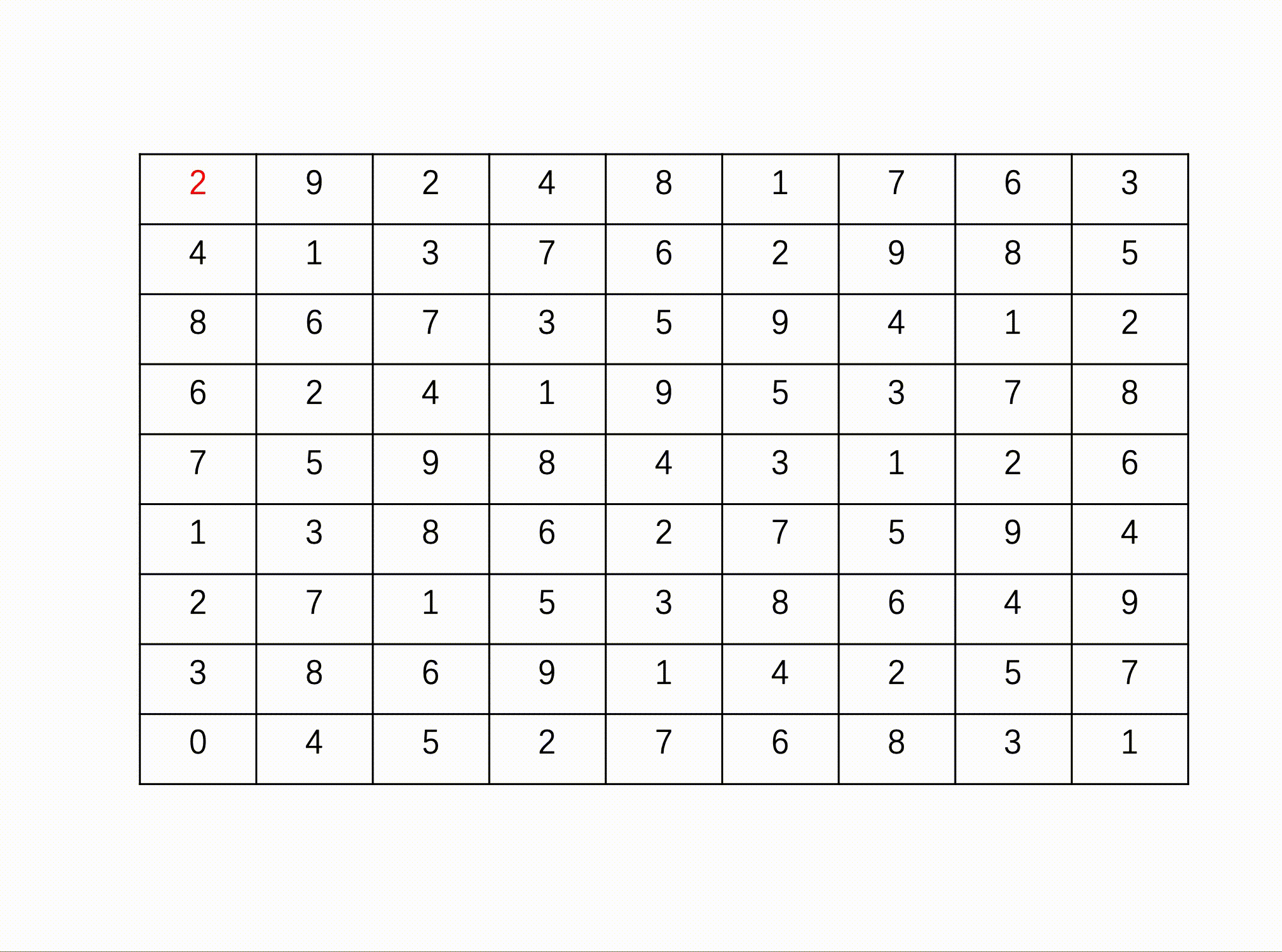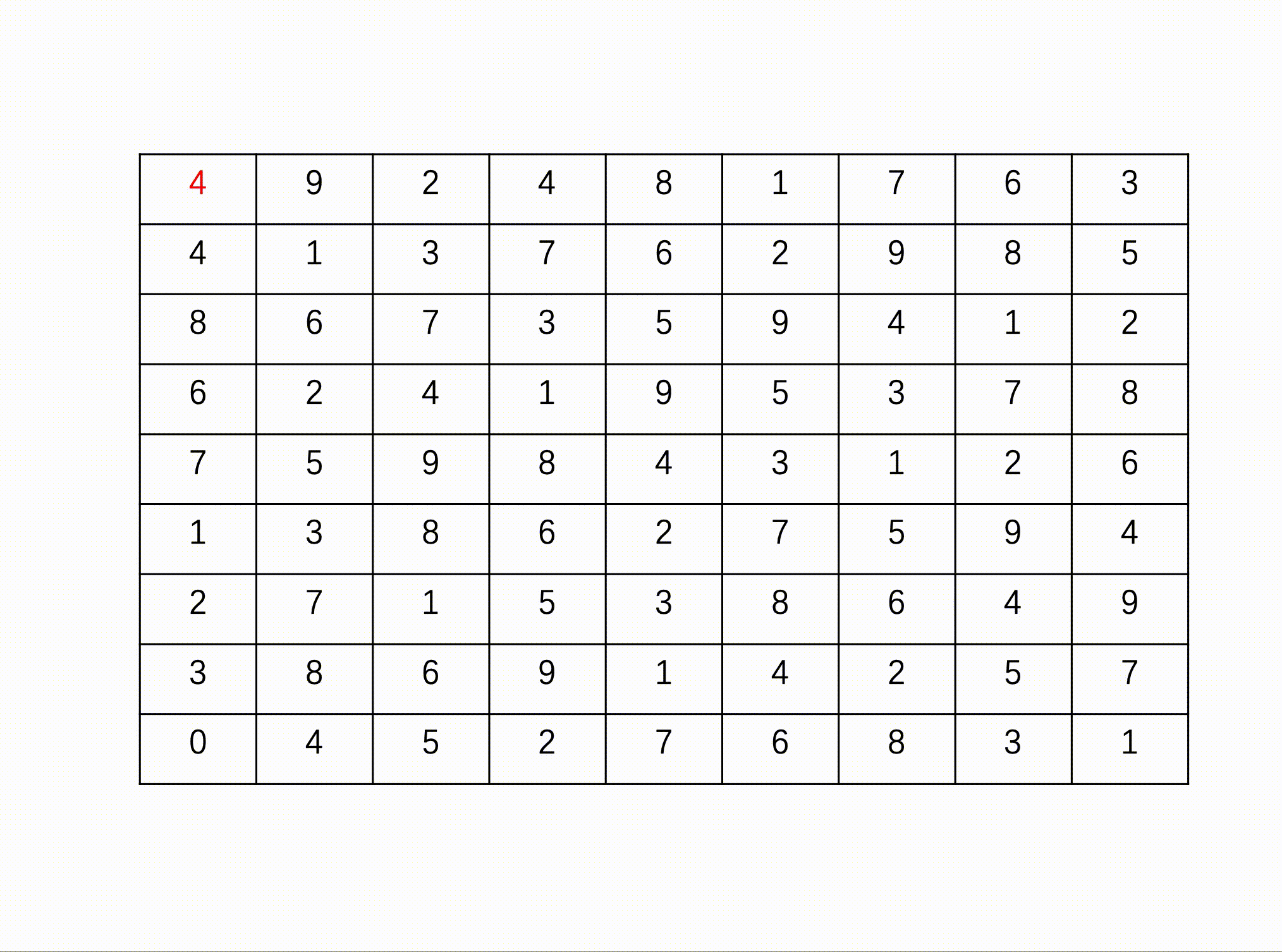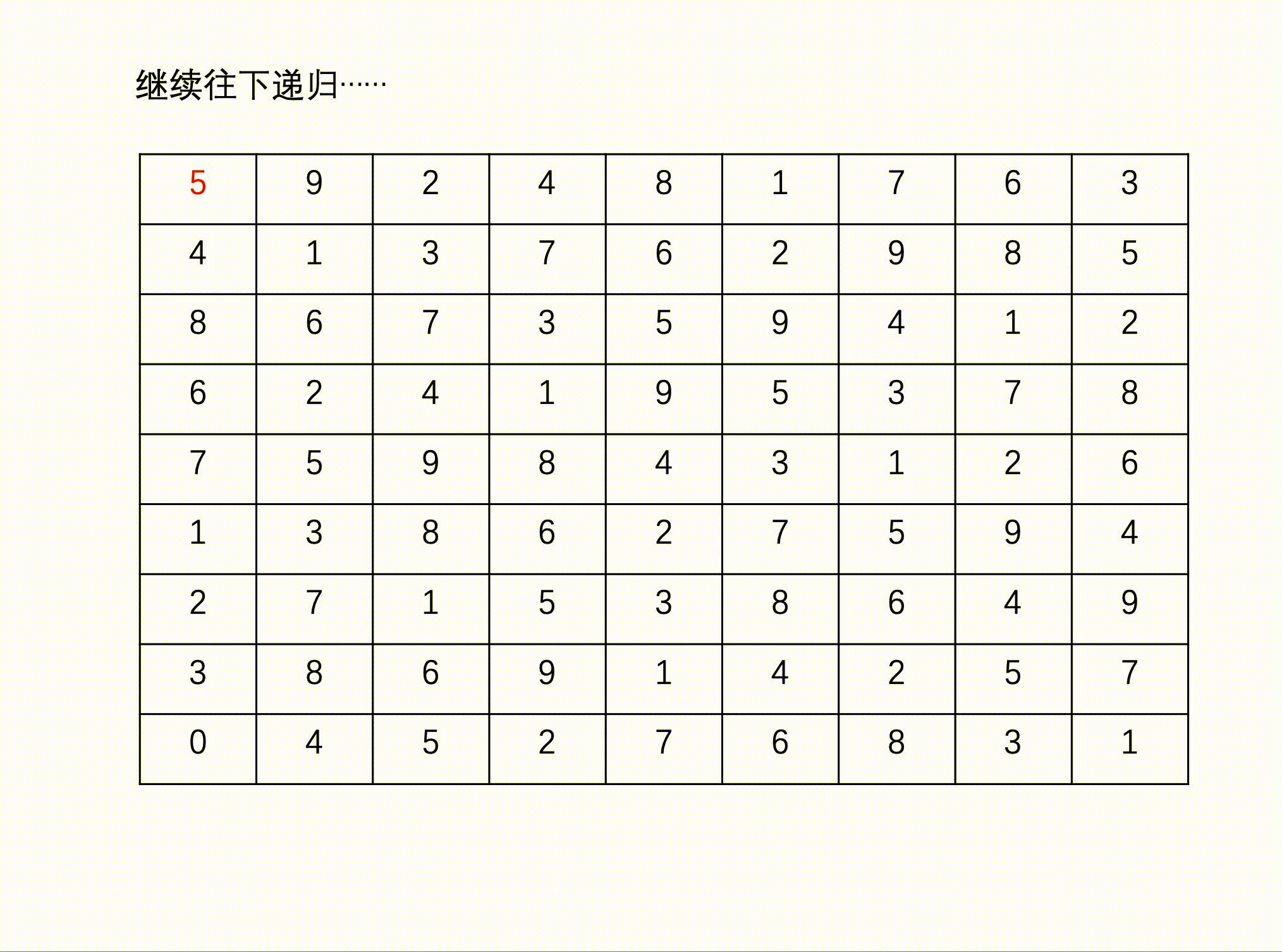
描述
问题描述:数独(Sudoku)是一款大众喜爱的数字逻辑游戏。玩家需要根据9X9盘面上的已知数字,推算出所有剩余空格的数字,并且满足每一行、每一列、每一个3X3****粗线宫内的数字均含1-9,并且不重复。
例如:
输入

输出

数据范围:输入一个 9*9 的矩阵
输入描述:
包含已知数字的9X9盘面数组[空缺位以数字0表示]
输出描述:
完整的9X9盘面数组
方法一:递归
#include <iostream>
using namespace std;
int num[9][9];//用于保存9x9盘面
bool flag = false;//flag为true时表示推算完成,结束递归
bool check(int n){//判断当前位置的值是否满足条件
int h = n / 9;//行号
int l = n % 9;//列号
for (int i = 0; i < 9; ++i){//同一列中不能有重复
if (i != h && num[i][l] == num[h][l]){
return false;
}
}
for (int j = 0; j < 9; ++j){//同一行中不能有重复
if (j != l && num[h][j] == num[h][l]){
return false;
}
}
for (int i = h / 3 * 3; i < h / 3 * 3 + 3; ++i){//九宫格内不重复
for (int j = l / 3 * 3; j < l / 3 * 3 + 3; ++j){
if ((i != h || j != l) && num[i][j] == num[h][l]){
return false;
}
}
}
return true;
}
void dfs(int n)
{
if (n == 81){//如果已经递归到右下角,输出整个盘面,并置flag为true,结束递归
for (int i = 0; i < 9; ++i){
for (int j = 0; j < 8; ++j){
cout << num[i][j] << ' ';
}
cout << num[i][8] << endl;
}
flag = true;
return;
}
int h = n / 9;//行号
int l = n % 9;//列号
if (num[h][l] == 0){//如果当前位置为0,说明需要推算
for (int i = 1; i <= 9; ++i){//枚举1-9的数字,判断哪个满足条件
num[h][l] = i;
if (check(n)){//判断当前数字是否满足条件
dfs(n + 1);//如果满足条件继续往下递归
if (flag){//如果flag为true表示整个盘面的递归结束了
return;
}
}
}
num[h][l] = 0;//需要回溯,恢复num[h][l]的值为0
}else{//当前位置不为0,往下一格递归
dfs(n + 1);
}
}
int main()
{
for (int i = 0; i < 9; ++i){
for (int j = 0; j < 9; ++j){
cin >> num[i][j];//输入9x9盘面
}
}
dfs(0);//从左上角开始递归
return 0;
}
方法二:
#include <iostream>
using namespace std;
int num[9][9];//用于保存9x9盘面
int row[9][9]={0};
int col[9][9]={0};
int block[3][3][9]={0};
bool flag = false;//flag为true时表示推算完成,结束递归
bool check(int n,int num){//判断当前位置的值是否满足条件
int h = n / 9;//行号
int l = n % 9;//列号
if(row[h][num-1] == 1||col[l][num-1] == 1|| block[h/3][l/3][num-1]==1){
return false;
}
return true;
}
void dfs(int n){
if (n == 81){//如果已经递归到右下角,输出整个盘面,并置flag为true,结束递归
for (int i = 0; i < 9; ++i){
for (int j = 0; j < 8; ++j){
cout << num[i][j] << ' ';
}
cout << num[i][8] << endl;
}
flag = true;
return;
}
int h = n / 9;//行号
int l = n % 9;//列号
if (num[h][l] == 0){//如果当前位置为0,说明需要推算
for (int i = 1; i <= 9; ++i){//枚举1-9的数字,判断哪个满足条件
num[h][l] = i;
if (check(n,i)){//判断当前数字是否满足条件
//更新每行、每列、每九宫格值的信息
row[h][i-1] = 1;
col[l][i-1] = 1;
block[h/3][l/3][i-1] = 1;
dfs(n + 1);//如果满足条件继续往下递归
if (flag){//如果flag为true表示整个盘面的递归结束了
return;
}
//回溯
row[h][i-1] = 0;
col[l][i-1] = 0;
block[h/3][l/3][i-1] = 0;
}
}
num[h][l] = 0;//需要回溯,恢复num[h][l]的值为0
}else{//当前位置不为0,往下一格递归
dfs(n + 1);
}
}
int main()
{
for (int i = 0; i < 9; ++i){
for (int j = 0; j < 9; ++j){
int temp;
cin >> num[i][j];//输入9x9盘面
temp = num[i][j];
if(temp!=0){//记录每行、每列、每九宫格值的信息
row[i][temp-1] = 1;
col[j][temp-1] = 1;
block[i/3][j/3][temp-1] = 1;
}
}
}
dfs(0);//从左上角开始递归
return 0;
}
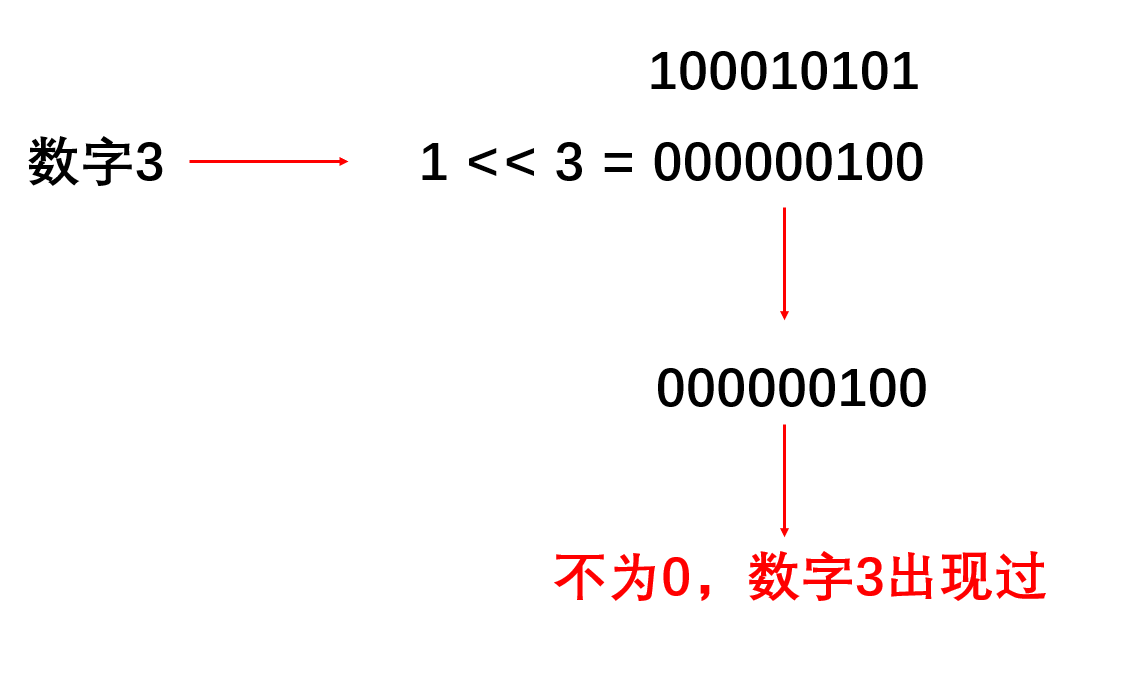
方法二:递归空间优化(位运算)
#include<iostream>
#include<vector>
using namespace std;
vector<vector<int> > sudoku(9, vector<int>(9, 0)); //记录数独矩阵
vector<int> col(9, 0); //用数字记录每列1-9是否有被使用过
vector<int> row(9, 0); //用数字记录每行1-9是否有被使用过
vector<vector<int> > block(3, vector<int>(3, 0)); //用数字记录每个方块1-9是否有被使用过
vector<pair<int, int> > space; //记录空缺的位置
void flip(int i, int j, int num){ //将第num位由0变成1或者由1变回0
row[i] ^= (1 << num);
col[j] ^= (1 << num);
block[i / 3][j / 3] ^= (1 << num);
}
void dfs(int pos, bool& valid){ //dfs搜索每一种情况
if(pos == space.size()){ //填充到空缺结尾,结束
valid = true;
return;
}
auto p = space[pos];
for(int i = 0; i < 9 && !valid; i++){ //遍历1-9,尝试每个数字
int mask = 1 << i; //找打第i位
//后续三个第i位都不能为1才代表可以使用该数字
if(!(mask & row[p.first]) && !(mask & col[p.second]) && !(mask & block[p.first / 3][p.second / 3])){
flip(p.first, p.second, i); //第i位置为1
sudoku[p.first][p.second] = i + 1;
dfs(pos + 1, valid); //递归找下一个
flip(p.first, p.second, i); //回溯
}
}
}
int main(){
for(int i = 0; i < 9; i++)
for(int j = 0; j < 9; j++){ //输入矩阵
cin >> sudoku[i][j];
if(sudoku[i][j] == 0) //如果缺少,坐标加入缺少的数组
space.push_back(make_pair(i, j));
else{ //否则行列块都记录这个数字出现过了
int num = sudoku[i][j];
flip(i, j, num - 1);
}
}
bool valid = false;
dfs(0, valid);
for(int i = 0; i < 9; i++){ //输出
for(int j = 0; j < 9; j++){
cout << sudoku[i][j] << " ";
}
cout << endl;
}
return 0;
}
HJ45 名字的漂亮度
描述
给出一个字符串,该字符串仅由小写字母组成,定义这个字符串的“漂亮度”是其所有字母“漂亮度”的总和。
每个字母都有一个“漂亮度”,范围在1到26之间。没有任何两个不同字母拥有相同的“漂亮度”。字母忽略大小写。
给出多个字符串,计算每个字符串最大可能的“漂亮度”。
本题含有多组数据。
数据范围:输入的名字长度满足 1≤n≤10000
输入描述:
第一行一个整数N,接下来N行每行一个字符串
输出描述:
每个字符串可能的最大漂亮程度
/*
解题思路:笨方法——用「钱」式思维来思考
名字的漂亮度,其实就是比谁的名字更值钱!
我们将名字的字母对应的「数字」作为它的价钱,
比如 26 最高,1 则最低,按大小顺序排布。
那么,我们要得到名字的最大可能「漂亮度」,
就要使得,越高频出现的字母,价钱越高。
Better than OK? 来!我们一起开始写代码!
*/
#include <iostream>
#include <algorithm>
using namespace std;
//计算名字的最大可能漂亮度(最高价钱)的函数接口
int MostValuableName (string Name) {
int Alphabet[26] = {0}; //初始化一个数组,用于记录名字中不同字母出现的次数
int Price[26] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26}; //初始化一个价钱表
int MostValuable = 0; //初始化名字的最高价钱
for (int i = 0; i < Name.size(); i++) {
//大写字母的情况
if (Name[i] >= 'A' && Name[i] <= 'Z') {
Alphabet[Name[i] - 'A'] += 1; //累加字母的出现次数
}
//小写字母的情况
else if (Name[i] >= 'a' && Name[i] <= 'z') {
Alphabet[Name[i] - 'a'] += 1; //累加字母的出现次数
}
}
sort(Alphabet, Alphabet + 26);
for (int i = 0; i < 26; i++) {
MostValuable += Alphabet[i] * Price[i]; //依次取高频字母,对应地,依次取高价钱;
//正所谓「好货不便宜,便宜无好货」,哦,好像不对,
//应该是卖得越多的货的价钱越高,就越赚钱!!!
}
return MostValuable; //返回一个名字的最大可能价钱(即漂亮度)
}
//计算多个名字的最大可能漂亮度(最高价钱)的函数接口
int MaximumPriceOfName (int Number) {
string Name; //字符串形式的名字
for (int i = 0; i < Number; i++) {
cin >> Name; //输入名字
cout << MostValuableName (Name) << endl; //输出名字的最大可能漂亮度
}
return 0;
}
//主函数
int main () {
int N; //需要计算最大可能漂亮的名字个数
while (cin >> N) {
MaximumPriceOfName (N); //输出多个名字的最大可能漂亮度
}
return 0;
}




